트랜스포머(Transformer) 모델
트랜스포머 모델은 Seq2Seq 모델, 어텐션 이후 NLP 분야에서 나온 또 하나의 큰 도약이다. 트랜스포머 모델의 아이디어는 Seq2Seq + 어텐션 모델에서 RNN 구조를 제거하는 것이다. 즉 RNN을 사용하지 않고 오직 어텐션 연산(과 FC 연산)만 사용한 모델이 트랜스포머 모델이다.[1]
왜 RNN을 제거했을까
시퀸스 형태의 데이터는 각 항목의 값 뿐만 아니라 그 순서도 중요하다. "John loves Sarah"와 "Sarah loves John"은 단어는 모두 같지만 순서가 달라 의미가 다르다. 즉 시퀸스 형태의 데이터를 다루기 위해서는 순서 정보를 처리할 수 있는 모델을 사용해야 한다.
RNN은 연속적으로 입력을 받아들이고 은닉 상태를 업데이트하기에 시퀸스 형태의 데이터를 처리하기에 적합했다. Seq2Seq와 같은 모델에서는 바로 이 이유로 RNN을 사용했다(그 당시엔 RNN을 제외하면 사실상 다른 대안이 없었다).
하지만 이전 글에서 설명했듯이 RNN은 단점이 많은 구조이다.
- 병렬화 문제 : RNN은 그 구조상 순차적으로 입력을 처리해야 하기에 병렬화가 불가능하다. 이 때문에 대규모의 데이터셋을 이용한 학습이 불가능하다(학습 시간이 너무 길어진다).
- long-term dependency 문제 : 시퀸스에서 멀리 떨어진 항목들 간의 관계성은 gradient vanishing/exploding 문제로 학습이 잘 되지 않는다.
이때 어텐션 연산은 위 두 가지 문제에 대한 해결책이 된다. 어텐션 연산은 병렬화가 가능하고, 각 query와 모든 key를 비교하기에 long-term dependency를 해결할 수 있다. 즉 이론적으로 어텐션 연산만을 사용한 모델은 RNN을 사용한 모델보다 학습이 빠르고, 그래서 더 큰 데이터셋에 대해서 학습시킬 수 있고, 더 좋은 성능을 낼 수 있다.[2]
어떻게 RNN을 제거했나 : Positional Encoding
하지만 무턱대고 RNN을 제거할 수는 없다. 상술했듯이 RNN은 시퀸스의 순서 정보를 처리할 수 있지만, 어텐션 연산은 순서 정보를 고려하지 않는다.
그래서 트랜스포머 모델에서는 모델에 입력되는 입력 임베딩(input embedding)에 positional encoding이라 불리는, 입력 임베딩과 같은 차원의, 위치 정보를 담고 있는 벡터를 더해준다.
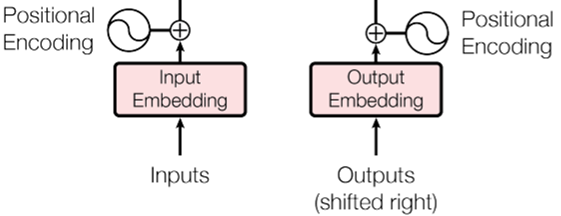
Fig.01 Positional Encoding
순서 정보를 입력해 주기 위해, 트랜스포머 모델에서는 모델에 입력되는 입력 임베딩에 positiona encoding을 더해준다.
입력 임베딩의 차원이
positional encoding 덕분에 같은 단어일 지라도 위치에 따라 다른 임베딩 벡터를 갖게 되어 위치 정보가 성공적으로 모델에 전달된다.
그런데 사실 위치 정보를 담고 있는 벡터를 만드는 방법에는 위 식을 이용하는 방법만 있는 것이 아니다. 이와 관련된 조금 더 자세한 정보는 다음 문서를 참고하자.
트랜스포머 모델의 구조
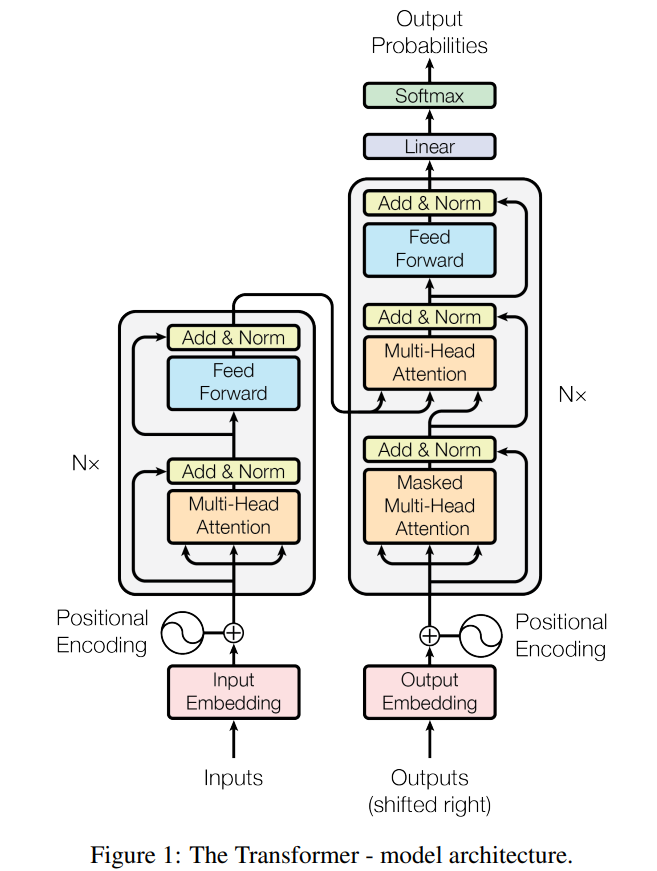
Fig.02 Transformer
트랜스포머 모델은 Seq2Seq 모델과 마찬가지로 인코더-디코더 구조로 되어 있다.
트랜스포머 모델은 Seq2Seq 모델과 마찬가지로 입력 시퀸스를 받아들이는 인코더와 출력 시퀸스를 출력하는 디코더로 이루어져 있다.[3]
인코더는 인코더 레이어를 여러 개 쌓아, 디코더는 디코더 레이어를 여러 개 쌓아 구성된다.
인코더 레이어는 multi-head self attention 연산과 position-wise fully connected feed forward 연산을 수행한다.
디코더 레이어는 multi-head self attention 연산과 multi-head cross attention 연산, 그리고 position-wise fully connected feed forward 연산을 수행한다.
각 부분에 대해 조금 더 자세히 알아보자.
인코더
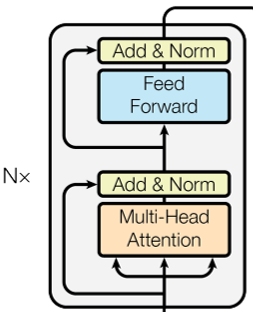
Fig.03 Transformer Encoder
트랜스포머 인코더는 인코더 레이어를
트랜스포머 인코더는 인코더 레이어(encoder layer)를
하나의 인코더 레이어 안에는 multi-head self attention 연산을 수행하는 서브 레이어(주황색 블록)와 position-wise fully connected feed forward 연산을 수행하는 서브 레이어(파란색 블록), 이렇게 두 개의 서브 레이어(sub-layer)가 있다(각 연산들에 대한 자세한 설명은 아래를 참조하자). 각 서브 레이어의 출력은 서브 레이어로의 입력과 더해진 후(residual connection) layer normalize되어(노란색 블록) 다음 서브 레이어의 입력으로 들어간다.
디코더
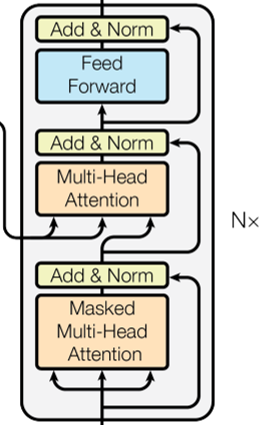
Fig.04 Transformer Decoder
트랜스포머 디코더는 디코더 레이어를
트랜스포머 디코더는 디코더 레이어(decoder layer)를
디코더 레이어는 masked multi-head self attention 서브 레이어(첫 번째 주황색 블록)와 multi-head cross attention 서브 레이어(두 번째 주황색 블록), 그리고 position-wise fully connected feed forward 서브 레이어(파란색 블록), 이렇게 세 개의 서브 레이어(sub-layer)로 구성된다. 각 서브 레이어의 출력은 residual connection으로 전달받은 입력을 더한 후 layer normalization을 거쳐(노란색 블록) 다음 서브 레이어의 입력으로 사용된다.
Seq2Seq vs. Seq2Seq + Attention vs. Transformer
Seq2Seq 모델, Seq2Seq + 어텐션 모델, 트랜스포머 모델의 인코더를 비교해 보면 다음과 같다.
| Seq2Seq | Seq2Seq + Attention | Transformer | |
|---|---|---|---|
| 핵심 연산 | RNN Cell | RNN Cell | multi-head self attention |
| 입력 | 입력 시퀸스 ( batch_len, seq_len, input_dim) | 입력 시퀸스 ( batch_len, seq_len, input_dim) | 입력 시퀸스 + positional encoding ( batch_len, seq_len, input_dim) |
| 출력 | 마지막 시점에서의 은닉 상태 ( batch_len, hidden_dim) | 매 시점에서의 은닉 상태 ( batch_len, seq_len, hidden_dim) | 마지막 인코더 레이어의 출력 ( batch_len, seq_len, input_dim) |
(단, batch_len은 batch의 크기, seq_len은 입력 시퀸스의 길이, input_dim은 입력 시퀸스의 임베딩 차원, hidden_dim은 RNN의 은닉 상태의 차원)
트랜스포머 모델의 연산
트랜스포머 모델에서 사용하는 연산들에 대해 자세히 알아보자.
Multi-head Attention 연산
인코더, 디코더에서 사용하는 multi-head 어텐션 연산은 어텐션 연산을 병렬적으로 여러 번 실행하기 위한 기법이다. 여기서 head란 어텐션 연산을 수행하는 주체를 말하는 것이고, 즉 multi-head라 하면 (동일한 시퀸스에 대해) 여러 번의 어텐션 연산을 수행하겠다는 것이다. 동일한 소스에 대해
구체적으로, 시퀸스 길이가
query
, key , value 가 입력된다. - 인코더 레이어, 디코더 레이어에서 사용하는 multi-head self attention의 경우
= = = (이전 레이어의 출력)이다. - 디코더 레이어에서 사용하는 multi-head cross attention의 경우
= (이전 레이어의 출력) ≠ = = (인코더의 출력)이다. , , 는 크기 ( , ) 행렬이다.
- 인코더 레이어, 디코더 레이어에서 사용하는 multi-head self attention의 경우
각 head가 사용할 query, key, value 만들기
모든 head가 동일한 query, key, value를 사용하면 여러 '관점'을 가진 multi-head 어텐션 연산이 되지 않는다. 따라서
, , 에 가중치 행렬 , , 을 각각 곱해 번째 head가 사용할 query, key, value , , 를 만들어 준다( ). , , 는 각각 크기 ( , ), ( , ), ( , )인 행렬이고, 이렇게 구해진 , , 는 각각 크기 ( , ), ( , ), ( , )인 행렬이 된다. 는 각 head에서 사용하는 query, key의 차원이고, 는 각 head에서 사용하는 value의 차원이다. 실제 구현할 때는
개의 행렬 , , 를 번 각각 곱해 사용하기보단, 크기 ( , )인 행렬 , , 를 , , 에 한 번에 곱한 후, 그 결과값(크기 ( , )짜리 행렬)을 크기 ( , ), ( , ), ( , )로 잘라 사용한다.
어텐션 계산
각 head에서
, , 를 이용해 scaled dot product 어텐션 연산을 수행한다. - 위 계산으로 얻어지는 어텐션 값(attention value)은 크기 (
, )인 행렬이 된다. - 실제 구현할 때는 각 head별로 따로따로
번의 연산을 하는 것이 아니라 벡터 연산을 통해 한 번에 계산한다.
- 위 계산으로 얻어지는 어텐션 값(attention value)은 크기 (
각 head별 어텐션 값 합치기
각 head별 어텐션 값들을 모두 이어붙인 후(concatenate), 가중치 행렬
를 곱한다. 이렇게 얻은 값은 multi-head 어텐션의 최종 결과값이 된다. 는 크기 ( , ) = ( , )인 행렬이다.
참고로 트랜스포머 논문에서는
벡터 연산을 적극적으로 활용했기 때문에, multi-head 어텐션 연산의 비용은 그냥 어텐션 연산(single-head attention)의 비용과 비슷하다.
Masked Attention 연산
디코더에서 사용하는 어텐션 연산은 masked multi-head self attention 연산이다. 이는 어텐션 연산을 할 때 미래의 단어를 참고하지 못하도록 미래의 단어를 가리고(mask) 학습하는 것을 의미한다.
masking을 구현하는 방법은 여러 가지가 있겠지만, 트랜스포머 모델에서는 mask 행렬을 이용하는 방식으로 구현한다. mask 행렬
: (key의) 번째 단어의 어텐션 값을 계산할 때 (query의) 번째 단어를 보면 안 되는 경우. 다시 말해, (query의) 번째 단어가 (key의) 번째 단어보다 미래에 위치하는 경우. : 나머지 경우
이 mask 행렬을 가지고 masked 어텐션을 계산하는 방법은 다음과 같다.
어텐션 스코어 계산 : 주어진 query
, key , value 에 대해, scaled dot product 어텐션 스코어 를 계산한다. 는 크기 ( , )인 행렬이 된다( : query, key 벡터의 차원) 는 (query에서의) 번째 단어와 (key에서의) 번째 단어가 얼만큼 연관되어 있는지를 나타낸다.
[추가] 마스킹 : 어텐션 스코어에 마스크 행렬
을 더해준다. 어텐션 분포 계산 : 마스킹된 어텐션 스코어 행렬
에 softmax 연산을 수행해 어텐션 분포 를 구한다. 는 크기 ( , )인 행렬이 된다. 인 경우, softmax 연산에 의해 는 0이 된다(즉 masking이 된 것이다).
어텐션 값 계산 : 어텐션 분포
와 value 행렬 를 곱해 어텐션 값 를 구한다. 는 크기 ( , )인 행렬이 된다( : value 벡터의 차원)
Position-wise Fully Connected Feed-Forward 연산
인코더, 디코더에 있는 position-wise fully connected feed forward 연산은 linear 연산과 ReLU를 이용해 다음과 같이 구현되어 있다.
: 크기 ( , )인 가중치 행렬 : 크기 ( , )인 가중치 행렬 : 크기 ( )인 bias 벡터 : 크기 ( )인 bias 벡터 : 입력 임베딩의 차원. 트랜스포머 모델에서는 이다. : feed forward 연산의 hidden layer의 차원. 트랜스포머 모델에서는 로 설정했다.
Layer Normalization 연산
인코더 레이어와 디코더 레이어에서는 각 서브 레이어(sub-layer)의 출력에 residual connection과 layer normalization을 적용한다. 이를 수식으로 나타내면 다음과 같다.
그래서 트랜스포머 모델을 처음 제안한 논문의 제목이 "Attention Is All You Need"이다. 즉 어텐션만으로도 충분하다는 뜻이다. 개인적으로 가장 잘 만든 논문 제목 중 하나라고 생각한다. ↩︎
이미지 처리 분야에서 아주 성공적으로 사용되는 CNN 구조도 위 두 가지 문제에 대한 해결책이 될 수 있다. CNN은 병렬화가 잘 되고, long-term dependency 문제도 여러 층의 layer를 쌓아(+ residual connection을 추가해) 해결할 수 있기 때문이다. 그래서 실제로 NLP 분야에 CNN을 사용한 모델도 많이 등장했다. 하지만 트랜스포머 모델에 비해 성능이 떨어져 오늘날엔 잘 사용되지 않는다. ↩︎
인코더-디코더 구조는 Seq2Seq 모델의 특징적인 구조이기에, 원래 인코더-디코더 모델이라 하면 Seq2Seq 모델을 의미하는 것이었다. 하지만 트랜스포머 모델의 성공으로, 오늘날 인코더-디코더 모델이라 하면 트랜스포머 모델을 의미하는 경우가 많아졌다. ↩︎
보통 인코더와 디코더의 레이어 수는 같게 설정한다. (필요에 따라 다르게 설정할 수도 있다.) ↩︎
Comments