문제상황
자연어와 같은 sequence 데이터들을 다루다 보면 짜증나는 요소가 하나 있는데, 바로 그 길이가 일정하지 않다는 것이다. 이미지 데이터의 경우 crop이나 resize 등으로 가로 세로 크기를 맞추고 진행하기에 모든 데이터들을 하나의 batch로 예쁘게 묶을 수 있다. 하지만 sequence 데이터는 길이가 다양해 하나의 batch로 묶기 쉽지 않다. 그렇다고 batch 연산을 포기하고 한 sequence씩 모델에 넣기에는 속도가 너무 느리다.
예를 들어 다음과 같은 문장들이 주어졌다고 해 보자.
- John lives in a beautiful mansion with a swimming pool.
- John loves to swim.
- John is a good swimmer.

tokenization 후[1] 각 문장의 길이는 각각 10, 4, 5로, 그 크기가 모두 제각각이다. 이들을 하나의 tensor로 만들어 batch 연산을 수행하고 싶다면 어떻게 해야 할까?
해결법
길이가 다른 sequence 데이터를 묶어 batch 연산을 수행하기 위해 사용할 수 있는 전략은 두 가지가 있다. 하나는 padding, 다른 하나는 packing이다. 사용하는 라이브러리에 따라, 사용하는 모델에 따라 둘 중 조금 더 적절한 방법이 있고, 이를 선택해 사용하면 된다.
Padding
Padding은 sequence들의 길이를 맞추기 위해 sequence 뒤에[2]에 아무런 의미 없는 값을 채워넣는 기법이다. 모델 입장에서는, 이 padding된 부분을 무시하고 연산을 수행하면 된다.
예를 들어 위 문장들의 예시에선, <pad>라는 의미 없는 값을 이용해 다음과 같이 padding을 수행할 수 있다.

이렇게 하면 이들을 모두 모아 크기 (3, 10)의 tensor로 만들 수 있다.
huggingface의 transformers 라이브러리의 경우 대부분의 모델이 padding을 사용한 batch 입력을 받을 수 있다. transformers에서는 일반적으로 (모델과 상응하는) tokenizer를 이용해 모델의 입력값을 만들게 되는데, 이때 padding=True, return_tensors="pt" 옵션을 주면 길이가 가장 긴 sequence에 맞춰 padding을 수행해 하나의 batch tensor를 만들어준다. 또 tokenizer는 attention mask라는 걸 반환하는데, 이는 attention 연산이 수행되어야 하는 token들은 1로, attention 연산이 수행되면 안 되는 token들은 0으로 표시해 놓은 tensor이다. padding의 경우 attention 연산이 수행되면 안 되므로 0으로 표시되어 있다. 이 attention mask를 모델에 함께 넣어줌으로서 모델은 padding된 부분에 대해 연산을 수행하지 않게 된다.
pytorch에서는 torch.nn.utils.rnn.pad_sequence() 함수를 이용해 padding을 수행할 수 있다. 다음과 같이 사용한다.
from torch.nn.utils.rnn import pad_sequence
pad_sequence(sequences, batch_first=False, padding_value=0.0)sequences: tokenize된 sequence(tensor)들의 list- 각 sequence는 첫 번째 차원(sequence 길이를 의미하는 차원)을 제외하고는 모두 같은 크기를 가져야 한다.
batch_first: batch 차원을 어디로 설정할지를 선택True면 반환값은 (batch_size, max_seq_len, ...)의 형태로,False면 (max_seq_len, batch_size, ...)의 형태로 반환된다.- 기본값은
False이다. - 참고로 huggingface의 transformers 라이브러리의 반환값은 batch 차원이 첫 번째 차원이므로, 만약
pad_sequence를 이용해 transformers 모델에 들어갈 입력값을 가공한다면batch_first=True로 놓고 사용하자.
padding_value: padding에 사용할 '무의미한' 값- 기본값은 0.0이다.
Packing
packed sequence는 RNN 기반 모델들에서 다른 길이의 sequence들을 batch 입력할 수 있도록 고안된 방법이다. transformer 기반 모델들의 경우 입력을 순차적으로 진행될 필요가 없지만(그래서 병렬화가 가능하고, 그래서 padded sequence 형태로 입력을 넣어줘도 되지만), RNN 기반 모델들의 경우 각 time step에 맞춰 순차적으로 입력이 진행되어야 한다.
즉 RNN 기반 모델들에서 batch 연산을 하기 위해서는, 모든 sequence의 첫 번째 항목들을 모두 모아 '한 번에' batch 연산을 수행하고, 모든 sequence의 두 번째 항목들을 모두 모아 '한 번에' batch 연산을 수행하고, ..., 이런식으로 수행해야 한다. 즉 sequence들을 '세로 방향으로' 읽어야 한다. '가로 방향'으로 읽으면 첫 번째 sequence의 첫 번째 항목, 두 번째 항목, ..., 마지막 항목까지 연산하고, 다시 모델을 초기화한 후, 두 번째 sequence의 첫 번째 항목, 두 번째 항목, ..., 이런식으로 연산이 진행되기 때문에 batch로 데이터를 처리할 수 없다.
말이 복잡한데, 예시를 보면 쉽다. 다음 3개의 문장에 packing을 적용하면,
우선 길이 순서대로 정렬하고, '가로 방향'이 아닌 '세로 방향'으로 값을 읽는다.
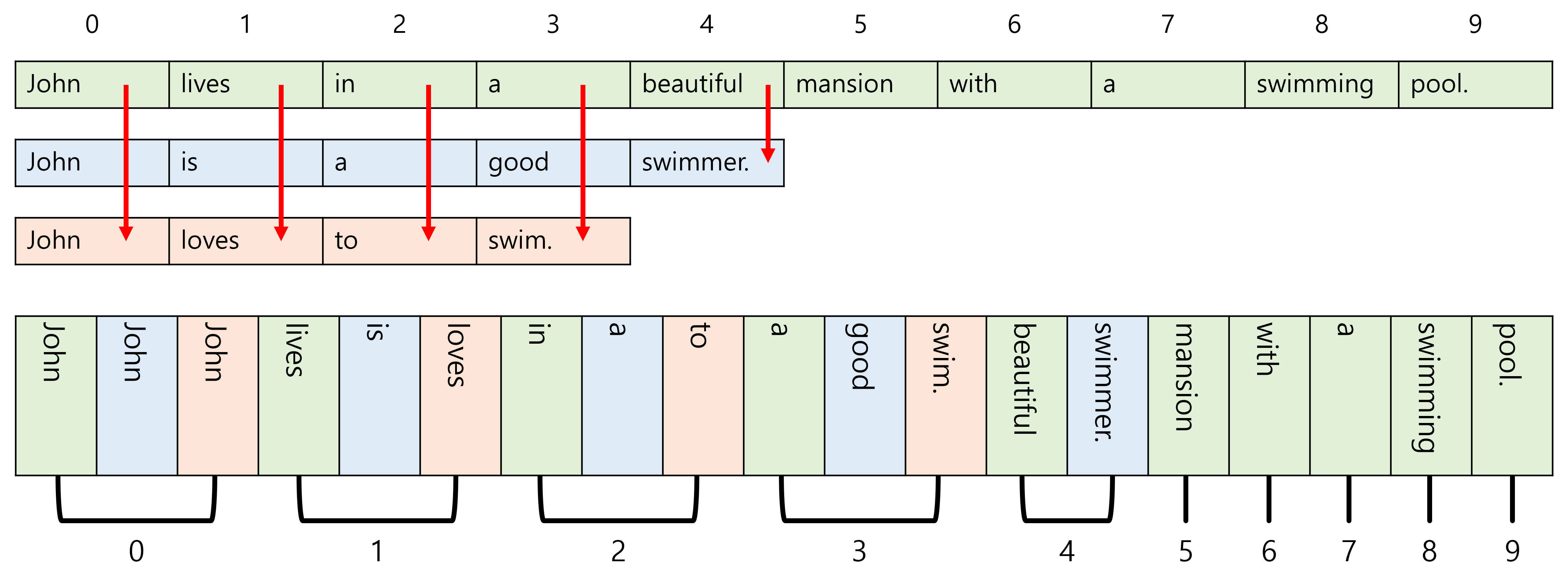
같은 색은 같은 sequence에서 왔음을 의미한다. 숫자는 각 항목들이 sequence의 몇 번째 항목인지를 나타낸다.
이제 다음과 같이 저장한다.
data: 세로 방향으로 읽은 데이터. 즉,["John", "John", "John", "lives", "is", "loves", "in", "a", "to", "a", "good", "swim.", "beautiful", "swimmer.", "mansion", "with", "a", "swimming", "pool"]batch_sizes: 각 time step마다 몇 개의 sequence 항목이 있는지 개수. 즉,[3, 3, 3, 3, 3, 1, 1, 1, 1, 1]
그럼 모델은 batch_sizes를 보고 현재 time step에 몇 개의 항목들이 batch로 계산되는지를 파악한 후 이에 맞춰 hidden states를 준비해 주고, data의 각 원소를 하나씩 읽어들여서 준비한 hidden states와 RNN 연산을 수행하게 된다.
packing 중 sequence들을 길이 순서대로 정렬하는 것이 중요한데, 이 정렬을 해 줘야 효율적으로 '세로 방향'으로 읽을 수 있기 때문에 그렇다. (supervised learning을 진행중이라면, sequence들을 길이 순서로 정렬해 준 후 레이블도 같은 순서로 맞춰줘야 함을 잊어버리지 말자.)
padded sequence도 '세로 방향'으로 읽으면 RNN 모델에 batch 입력을 할 수 있긴 하다. 하지만 RNN 모델에서는 packed sequence를 사용하는게 padded sequence를 사용하는 것보다 좋다. padded sequence를 입력하면 padding에 대해서도 RNN 연산이 수행되지만, packed sequence를 입력하면 입력 sequence의 항목들에 대해서만 RNN 연산이 수행되어 더 효율적이기 때문이다.
한편 transformer 기반 모델에서는 packed sequence가 가지는 이점이 딱히 없다. 상술했듯이 transformer에서는 입력 순서가 중요한 것이 아니기에 이렇게 복잡한 짓 할 필요 없이 그냥 padded sequence를 입력으로 넣어주면 된다.
pytorch에서는 torch.nn.utils.rnn.pack_sequence() 함수를 사용해 packing을 수행할 수 있다. 다음과 같이 사용한다.
from torch.nn.utils.rnn import pack_sequence
pack_sequence(sequences, enforce_sorted=True)sequences: tokenize된 sequence(tensor)들의 list- 각 sequence는 첫 번째 차원은 sequence의 길이를 나타내는 값이고, 나머지 차원은 아무런 제한이 없다.
pad_sequence()함수와 다르게 각 sequence가 다른 크기를 가져도(다른 차원을 가져도) 된다.
enforce_sorted:sequences로의 입력이 길이 순서대로 내림차순 정렬되어 있는지 확인할지를 선택True면sequences가 길이 순서대로 정렬되어 있지 않으면 에러 발생
이 함수의 반환값은 PackedSequence 객체이다. 이 객체는 data와 batch_sizes라는 속성을 가지고 있고, 각각의 의미는 상술한 그것과 같다.
여담
pack_padded_sequence()
사실 pack_sequence() 함수는 내부적으로 pad_sequence() 함수와 pack_padded_sequence() 함수를 순차적으로 호출하는 식으로 구현되어 있다. torch.nn.utils.rnn.pack_padded_sequence() 함수는 이름 그대로 padded sequence를 packed sequence로 변환해주는 함수로, 다음과 같이 사용한다.
from torch.nn.utils.rnn import pack_padded_sequence
pack_padded_sequence(input, lengths, batch_first=False, enforce_sorted=True)input: padded sequencelengths: 각 sequence의 길이를 나타내는 listbatch_first:input에 입력되는 tensor에서 batch가 첫 번째 차원인지를 나타내는 bool 값True면input의 첫 번째 차원은 batch를 나타내는 값이고(즉input은 (batch_size, max_seq_len, ...) 형태를 가진다),False면input의 두 번째 차원이 batch를 나타내는 값이다(즉input은 (max_seq_len, batch_size, ...) 형태를 가진다).- 기본값은
False이다.
enforce_sorted:input의 sequence들이 길이 순서대로 내림차순 정렬되어 있는지를 확인할지를 선택True면lengths가 길이 순서대로 정렬되어 있지 않으면 에러 발생.False면pack_padded_sequence()함수가 직접 정렬을 수행한다.- 기본값은
True이다.
pad_packed_sequence()
당연히 반대 역할을 하는 함수도 있다. torch.nn.utils.rnn.pad_packed_sequence() 함수는 packed sequence를 padded sequence로 변환해주는 함수로, 다음과 같이 사용한다.
from torch.nn.utils.rnn import pad_packed_sequence
pad_packed_sequence(sequence, batch_first=False, padding_value=0.0, total_length=None)input: packed sequence (PackedSequence객체)batch_first: batch 차원을 어디로 설정할지를 선택True면 반환값은 (batch_size, max_seq_len, ...)의 형태로,False면 (max_seq_len, batch_size, ...)의 형태로 반환된다.- 기본값은
False이다.
padding_value: padding에 사용할 '무의미한' 값- 기본값은 0.0이다.
total_length: padding할 크기를 지정None이 아니면total_length크기가 되도록 padding한다. 만약total_length가 지정되어 있는데 그 값이input의 sequence의 최대 길이보다 작으면 에러가 발생한다.None이면input의 sequence의 최대 길이를 기준으로 padding한다.- 기본값은
None이다.
Comments