강화학습(RL, Reinforcement Learning)이란?
강아지에게 "앉아!"를 훈련시키는 과정을 생각해 보자.
- 강아지에게 "앉아!"라 말한다.
- 처음에는 "앉아!"라는 말을 들어도 제 멋대로 행동할 것이다.
- 그래도 강아지에게 계속 "앉아!"라 말한다. 그러다 어느 순간 우연히 강아지가 앉으면 간식 등을 줘 이를 칭찬한다.
- 강아지는 (간식을 더 받기 위해) 이 행동, 저 행동을 해 보며, "앉아!"라는 말을 들었을 때 어떤 행동을 하는 것이 맞는지 찾는다.
- 몇 번의 시행착오 끝에, 강아지는 "앉아!"라는 말을 들었을 때 앉으면 보상이 뒤따른다는 사실을 알게 된다.
- 이제 강아지에게 "앉아!"라 말하면 강아지는 앉는다.
이 과정을 잘 보면, 강아지는 명시적인 선생 없이도 그저 주변 환경(environment)과의 상호작용(interaction)[1]을 통해 "앉아!"를 학습했다. 이런 식의 학습법은 갓난아이가 걷는 법을 배울 때, 어린 아이가 자전거 타는 법을 배울 때, 동물이 사냥하는 방법을 배울 때 등 정말 다양한 곳에서 볼 수 있다.
강화학습(RL, Reinforcement Learning)은 바로 이런 식의 학습법을 의미한다. 조금 더 형식적으로 말하면, RL은 에이전트(agent)가 환경(environment) 내에서 받을 수 있는 보상(reward)의 총합을 최대화하기 위해 각 상황(situation)에서 어떻게 행동(action)해야 하는지를 학습하는 학습법을 의미한다. 강아지에게 "앉아!"를 훈련하는 위 경우엔 에이전트는 강아지이고, 환경은 "앉아!"라 말하고 간식을 주는 주인이고, 보상은 간식이다. 강아지는 주인이 "앉아!"라 말하는 현재 상황에서 다양한 행동(ex. 눕기, 뛰기, 걷기, 짖기 등)을 할 수 있지만, 그 중 앉기를 했을 때 보상이 제일 크다(= 간식을 받을 수 있다)는 것을 시행착오(trial-and-error search) 를 통해 알게 된다. 시행착오는 다른 학습법에는 없고 오직 RL에만 있는, RL의 중요한 특징 중 하나이다.
다른 학습법에는 없고 RL에만 있는, RL의 또 다른 중요한 특징으로는 지연된 보상(delayed reward) 이 있다. RL에서의 보상은 즉각적이지 않을 수 있다. 예를 들어 체스 게임에서, 에이전트의 보상은 체스 말을 움직이는 행동 직후가 아닌 체스 게임의 승패가 결정났을 때 주어진다. 그래서 에이전트는 순간 순간의 보상을 최대화하는 선택이 아닌, (특정 기간 동안의) 전체 보상의 합을 최대화하는 선택을 해야 한다. 바로 이 점이 RL을 어렵게, 또 그리고 흥미롭게 만드는 요소이다.
참고로 RL은 학습법이란 의미 뿐만 아니라, 환경 안에서 받을 수 있는 보상의 총합을 극대화하는 문제, 그리고 이런 문제와 해결법(학습법)을 다루는 학문 분야라는 의미로도 사용된다. 이 세가지 뜻은 유사하지만 집중하는 부분이 조금씩 다르기에, RL이라는 말을 보면 주변 문맥을 잘 읽어 어느 의미로 사용되었는지를 파악해야 한다.
RL vs. 지도학습(Supervised Learning) vs. 비지도학습(Unsupervised Learning)
일반적으로 기계학습은 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 그리고 RL, 이렇게 3가지로 구분한다. 이 세 학습법을 비교하면 다음과 같다.
학습 데이터
- 지도학습 : 레이블링(labeling)된 예제(example)들로 이루어진 학습 데이터가 주어진다. 이 데이터들은 에이전트가 어떤 행동을 하는 것이 정답인지(= 최고의 행동인지) 알려주는 값으로, 에이전트가 이전에 취한 행동들과는 독립적이다. 참고로 이 데이터를 Instructive Feedback이라고도 한다.[2]
- 비지도학습 : 레이블링 되지 않은 예제들로 이루어진 데이터가 주어진다.
- RL : 에이전트가 환경가 상호작용해 획득한 경험(experience) 데이터가 주어진다. 이 데이터들은 에이전트가 취한 행동이 얼마나 좋은지를 알려주는 값으로, 에이전트가 이때까지 취한 행동에 종속적이다. 그러나 이들 값은 어떤 행동이 최고의 행동인지는 알려주진 않는다. 참고로 이 데이터를 Evaluative Feedback이라고도 한다.
학습 목표
- 지도학습 : 모델(model)이 학습 데이터로부터 일반화(generalize)된 정보를 습득하게 해, 학습 데이터에서 등장하지 않은 상황에서도 올바른 예측을 할 수 있게 하는 것이 목표이다.
- 비지도학습 : 데이터에서 숨겨진 구조(structure) 및 특징(feature)을 찾아내는 것이 목표이다.
- RL : 에이전트가 주어진 환경을 잘 파악하여, 최종적으로 획득하는 보상의 총합이 가장 크도록 하는 것이 학습의 목표이다.
Exploitation vs. Exploration
환경 안에서 에이전트가 할 수 있는 행동은 Exploitation(활용), Exploration(탐색), 이렇게 두 가지로 크게 분류할 수 있다.
- Exploitation(활용) : 많은 보상을 얻기 위해, 과거에 시도해 보았던 행동 중 가장 큰 보상을 만드는 행동을 한다.
- Exploration(탐색) : 가능한 행동의 종류를 찾기 위해, 과거에 시도해보지 않았던 행동을 한다.
예를 들어 음식점을 선택하는 문제에서, 평소에 자주 가던 맛집을 가는 것은 Exploitation이다. 반면 새로운 맛집을 찾아보는 것은 Exploration이다.[3] 또한 환자에게 약을 투여하는 상황에서, 이미 검증된 약을 사용하는 것은 Exploitation이다. 반면 새로운 신약을 시험해보는 것은 Exploration이다.[4]
Exploitation과 Exploration 중 어떤 것을 선택해야 할까? 이 문제를 Exploitation-Exploration Dilemma라 부른다. 동시에 두 가지 행동을 할 수는 없으므로, 한 종류의 행동을 하면 해당 행동을 하는 동안에는 다른 행동을 할 수 없다. 그러나 계속 한 가지 행동만 하면 별로 큰 보상을 얻지 못하게 된다. 이 딜레마는 지도학습이나 비지도학습에서는 발생하지 않는, RL만이 가진 독특한 딜레마로, 대부분의 RL 알고리즘들에서 중점적으로 다루는 문제이다.
RL의 핵심 요소
RL 시스템을 구성하는 핵심 요소는 정책(policy), 보상 시그널(reward signal), 가치 함수(value function), 모델(model), 이렇게 4가지가 있다.
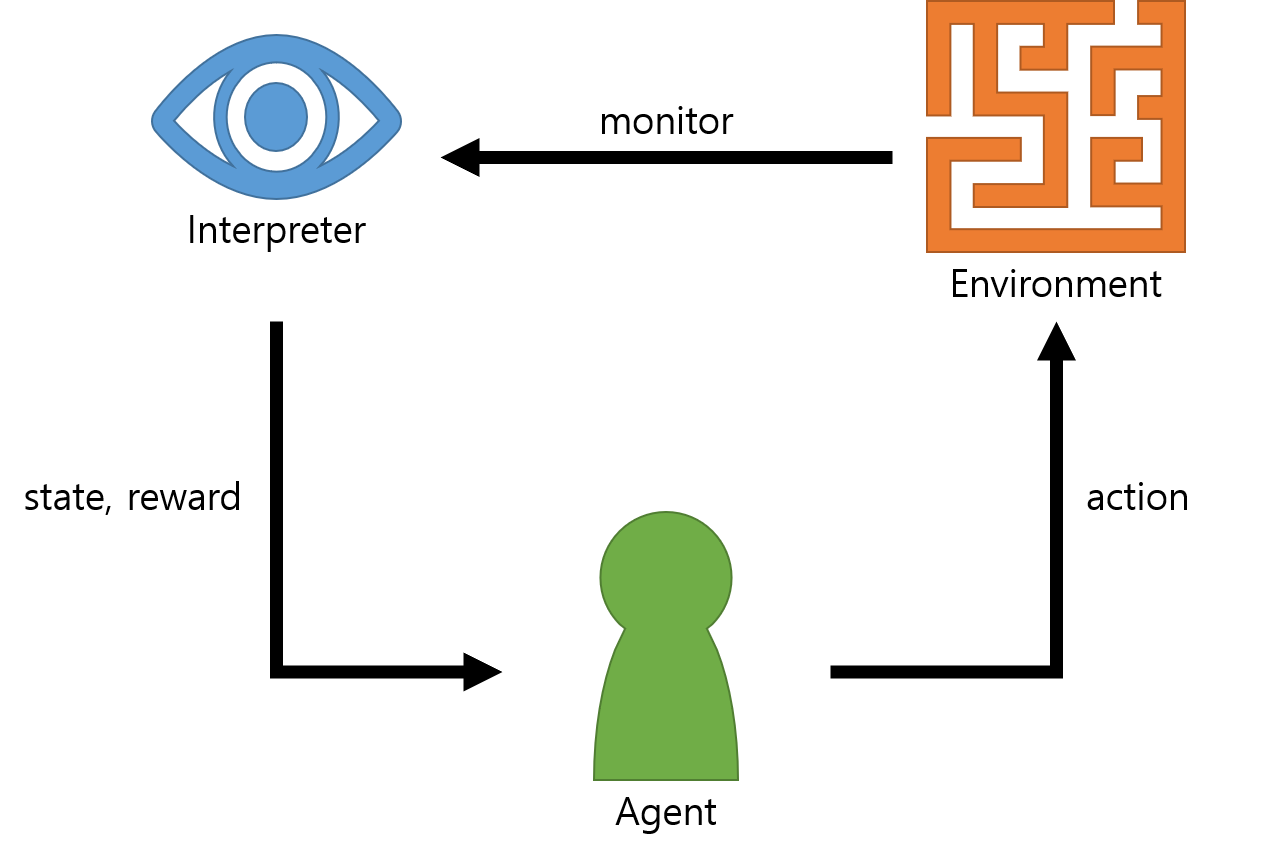
Fig.01 Main Element of RL
정책(policy)
정책(policy)은 특정 시간에 에이전트가 행동하는 방식을 결정한다. 즉 정책이란 현재 환경의 상태(state)를 입력값으로 받아 에이전트의 행동을 반환하는 일종의 함수라 할 수 있다.
정책은 두 가지 종류로 구분할 수 있다.
- 결정론적 정책(deterministic policy) : 특정 상태(state)에서는 반드시 특정 행동(action)을 하도록 정해져 있는 정책
- 확률적 정책(stochastic policy) : 특정 상태(state)에서 어떤 행동(action)을 할 지 확률적으로 결정하는 정책
정책은 심리학에서의 자극-반응 규칙(stimulus-response rule)에 대응된다.
보상 시그널(reward signal)
보상 시그널(reward signal) 또는 보상(reward)은 RL 문제의 목표를 정의한다. 매 시간 간격마다(에이전트가 행동을 할 때마다) 환경은 에이전트에게 보상(reward)이라 부르는 실수값(real number) 하나를 제공한다. 에이전트의 유일한 목표는 장기적인 관점에서 이들 보상의 총합이 최대가 되게 하는 것이다. 즉 보상은 에이전트에게 무엇이 좋은지 무엇이 안 좋은지를 알려주는 값이다. 일반적으로 보상 시그널은 환경 상태와 실행한 행동을 입력값으로 받고 확률적으로(stochastic) 보상을 출력하는 함수 형태로 주어진다.
보상 시그널은 정책을 바꾸는 가장 중요한 지표 중 하나이다. 만약 현재의 정책으로 결정된 행동이 계속해서 낮은 보상을 만든다면, 미래에는 동일한 상황에 다른 정책을 적용하는 것이 좋을 것이다.
보상은 생명체가 받는 행복(pleasure) 또는 고통(pain)에 대응된다.
가치 함수(value function)
가치(value)란 현재 상태로부터 앞으로 받을 것으로 예상되는 모든 보상들의 총합을 의미한다. 보상이 현재 환경 상태가 좋은지 안좋은지에 대해 즉각적이고 본능적인 선호도(desirability)를 알려준다면, 가치는 장기적인 관점에서 앞으로 일어날 가능성이 높은 상태들과 이들로부터의 보상들에 대한 선호도를 의미한다고 할 수 있다. 그리고 가치 함수(value function)는 주어진 조건에서의 가치를 반환하는 함수이다.
의사를 결정하거나 결정한 의사를 평가할 때는 가치를 기준으로 해야 한다. 에이전트는 가장 높은 보상을 주는 행동이 아닌, 가장 높은 가치를 주는 행동을 선택해야 한다. 그래야 장기적인 관점에서 받을 수 있는 보상을 최대화할 수 있기 때문이다. 그러나 보상은 1차적인 값이고, 보상의 예측값인 가치는 2차적인 값이다. 보상이 없다면 가치도 없고, 가치를 예측하는 유일한 이유는 더 많은 보상을 받기 위함이다.
가치를 정확히 예측하는 일은 당연히 매우 어려운 일이다. 보상은 환경으로부터 곧바로 주어지지만, 가치는 에이전트가 생애 내내 관측한 결과들을 토대로 만든 추정값이기 때문이다. 따라서 대부분의 RL 알고리즘은 어떻게 하면 효율적이고 정확하게 가치를 추정할지를, 다시 말해 가치 함수를 만들지를 핵심적으로 다룬다.
모델(model)
모델(model)이란 환경의 동작을 모사하거나, 환경이 어떻게 동작할지를 추정한 것이다. 모델은 상태와 행동을 입력값으로 받아 앞으로의 상태와 보상을 예측해 출력하는 일종의 함수이다. RL 알고리즘에 따라 모델을 사용할 수도, 사용하지 않을 수도 있다.
모델은 planning에 사용된다. planning이란 미래에 일어날 상황들을 고려하여 행동을 결정하는, 시행착오의 반댓말이다. RL 알고리즘은 모델과 planning을 이용해 학습을 진행하는 모델 기반 방법(model-based method)과, 모델과 planning을 사용하지 않고 시행착오만을 이용해 학습을 진행하는 model-free method로 구분할 수 있다.
RL vs. 진화적 방법(evolutionary method)
RL 문제를 풀기 위한 방법에는 가치 함수를 추정해 사용하는 RL 방법뿐만 아니라, 유전 알고리즘(genetic algorithm), 유전 프로그래밍(genetic programming), simulated annealing 등과 같이 가치 함수를 사용하지 않는 다양한 최적화 방법도 있다. 이 방법들은 마치 생명체가 진화하는 것과 닮아 진화적 방법(evolutionary method)이라 부른다. 진화적 방법은 일반적으로 다음과 같은 방식으로 동작한다.
- 환경과 각각 상호작용하는 독립적인 인스턴스(instance)들을 여러 개 만든다.
- 여러 개의 정적인(static) 정책들을 각 인스턴스에 장기간 적용한다.
- 각 인스턴스가 최종적으로 받게 되는 보상을 확인한다.
- 이들 중 가장 큰 보상을 받은 정책과 이를 무작위로 변형한 정책들(random variants)을 가지고 2번부터 반복한다. 참고로 이렇게 한 바퀴 도는 것을 한 세대(generation)라 부른다.
진화적 방법은 다음 경우에 사용하기 좋다.
- 선택 가능한 정책의 종류가 적다(= 정책 공간(space of policies)이 작다).
- 좋은 정책이 흔하고 찾기 쉽다.
- 탐색에 많은 시간을 들일 수 있다.
- 에이전트가 환경에 대한 완전한 정보를 알 수 없다.
RL과 진화적 방법은 일견 유사해 보이지만 많은 차이가 있다. RL에서는 환경과 상호작용을 하는 동안 학습이 이루어지는 반면, 진화적 방법은 환경과의 상호작용을 통해 학습하지 않는다. 또한 진화적 방법은 정책이 한 행동에서 다른 행동으로 가는 함수라는 사실을 활용하지 않는다. 그리고 RL에서는 에이전트가 겪은 상태와 취한 행동 정보를 사용해 학습이 이루어지지만, 진화적 방법은 그런 정보를 사용하지 않고 오직 정책과 그로 인한 보상만을 토대로 학습이 이루어진다.
즉 진화적 방법은 RL에 비해 정보를 덜 사용하는 학습법이다. 물론 RL이 진화적 방법보다 추가로 더 쓰는 정보가 잘못되어(ex. 상태값이 잘못 수집한(misperceived) 경우 등) 잘못된 방향으로 학습이 이루어질 수도 있지만, 일반적으로는 RL을 사용하면 진화적 방법을 사용하는 것보다 더 효율적인 탐색이 가능하다.
예시: Tic-Tac-Toe
tic-tac-toe 게임의 인공지능을 만들어 보자.
진화적 방법(evolutionary method)
진화적 방법으로 tic-tac-toe 게임의 인공지능을 만드려면 다음 과정을 거치면 된다.
1. 우선 여러 개의 초기 정책들을 구성한다. 여기서 정책이란 3×3 게임판에서 가능한 모든 경우에 대해[5] 다음에 어떤 행동을 할지를 적어 놓은 배열이다.
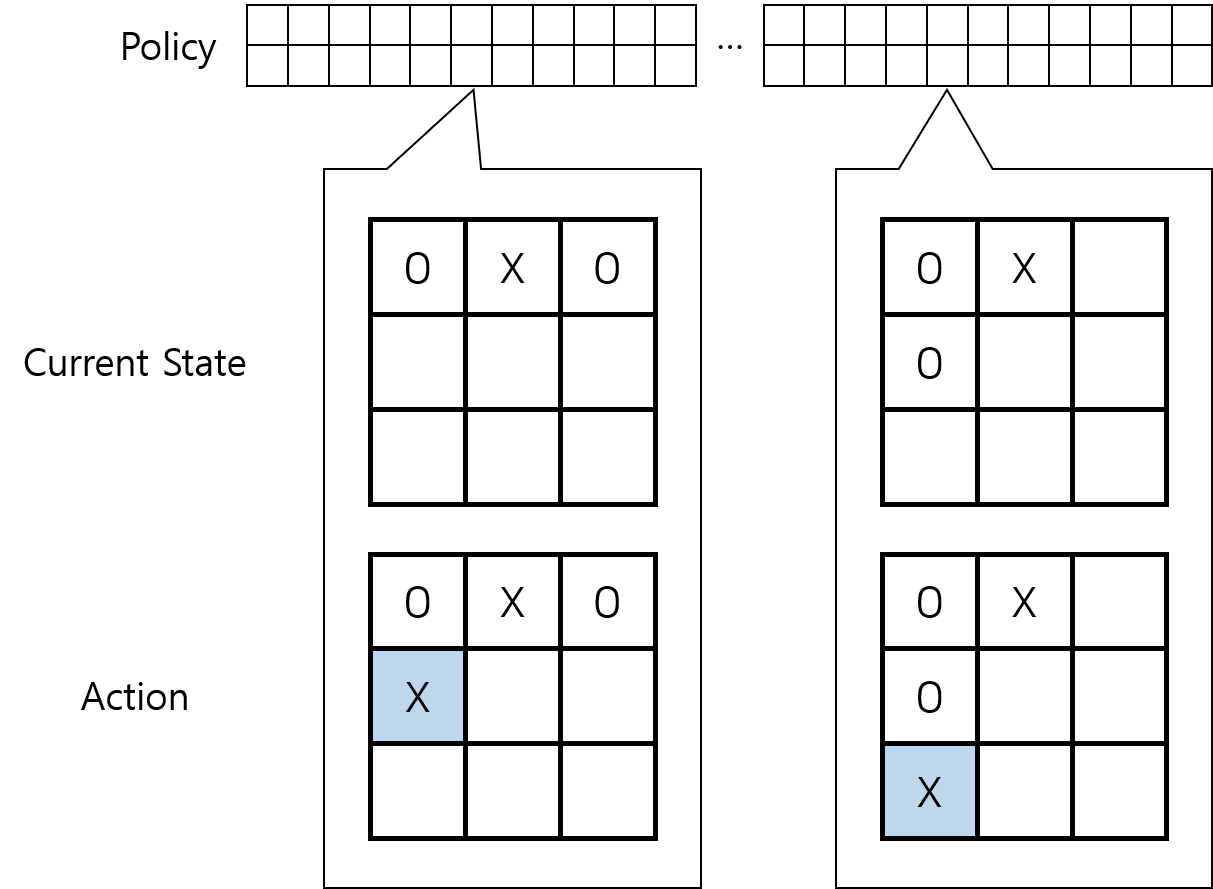
Fig.02 Tic-Tac-Toe 게임 - 진화적 방법 - 정책 1
다른 정책을 적용하면 다른 식으로 게임이 풀리게 된다.
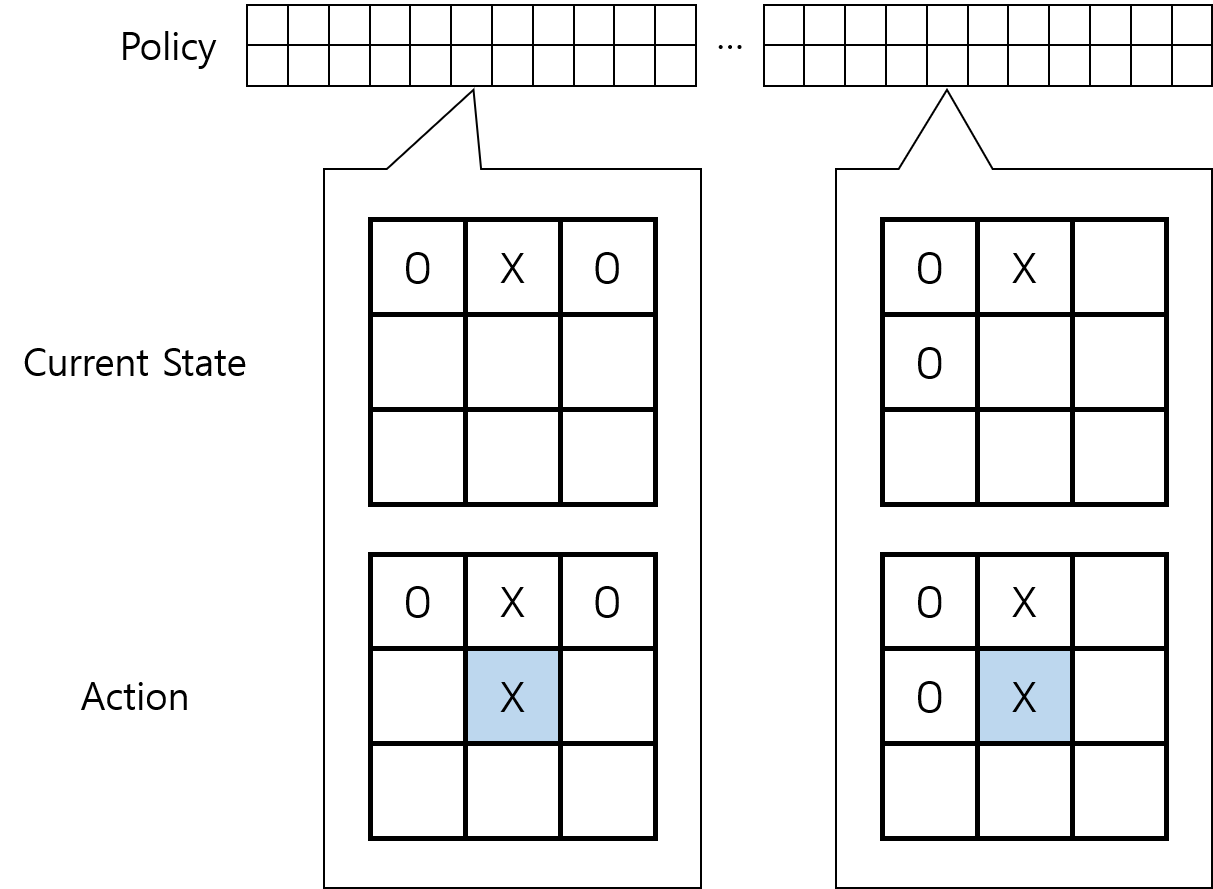
Fig.03 Tic-Tac-Toe 게임 - 진화적 방법 - 정책 2
2. 각 정책들에 대해, 정책이 시키는 대로 행동하며 적(opponent)과 여러 판의 게임을 진행한다. 게임 결과를 바탕으로 해당 정책을 적용했을 때의 승률을 추정한다.
3. 가장 승률이 높게 나온 정책과 그 변종들을 이용해 다시 2번을 반복한다. 이렇게 적과의 게임을 계속하며 가장 승률이 높은 정책을 계속 탐색해 나간다.
RL
RL 방법으로 tic-tac-toe 게임의 인공지능을 만드려면 다음 과정을 거치면 된다.
1. 가치 함수를 초기화한다. 가치 함수는 3×3 게임판에서 가능한 모든 경우에 대해 가치를 계산해 놓은 배열이다. 즉 만약 배열에서 상태 A의 가치가 상태 B의 가치보다 크게 되어 있다면, 상태 A가 상태 B보다 더 "좋은" 상태라는 뜻이다.
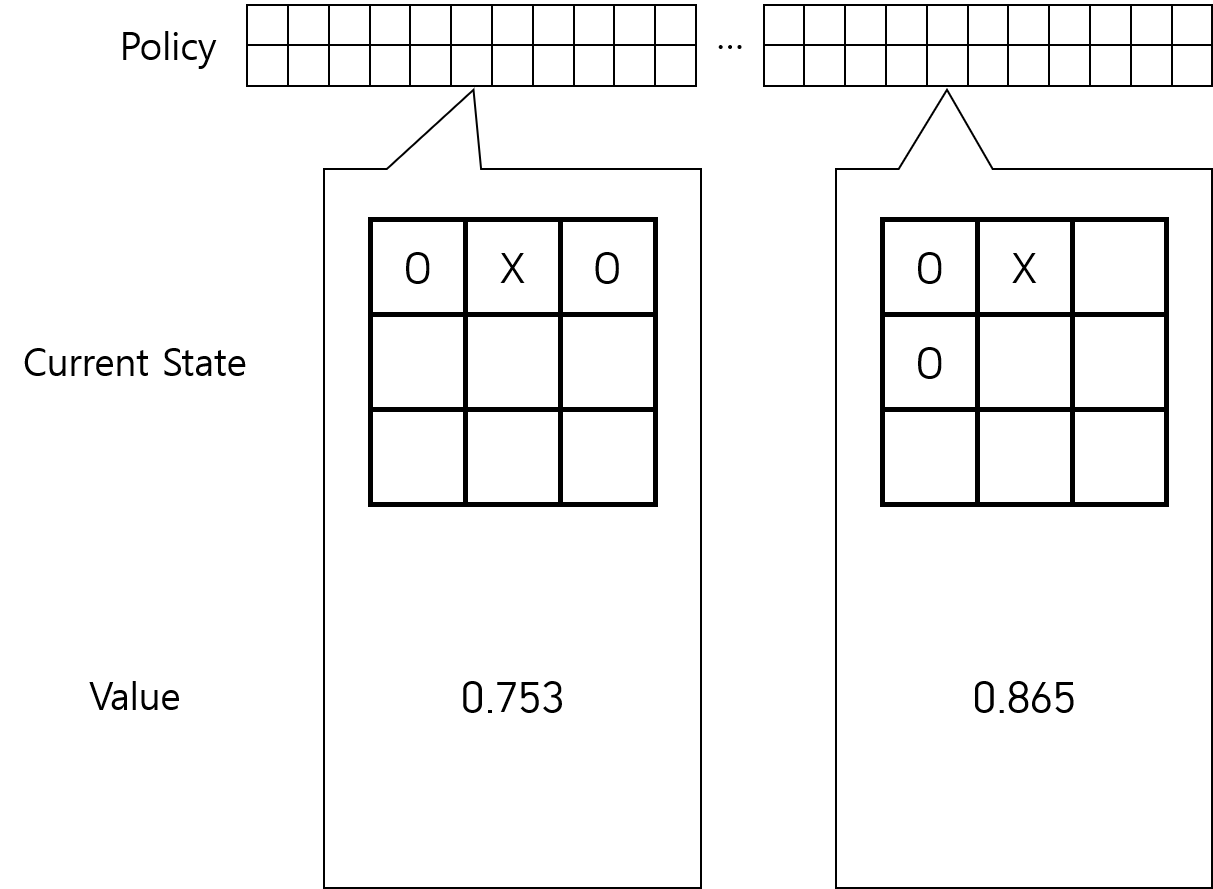
Fig.04 Tic-Tac-Toe 게임 - RL
가치 함수의 배열에서, X가 이기는 경우[6]의 가치를 1, X가 지는 경우의 가치를 0, 나머지 경우(아직 승부가 나지 않은 경우)의 가치를 0.5[7]로 초기화한다.
2. 적(opponent)과 게임을 한 판 진행한다. 에이전트가 취할 행동은 다음 방법으로 결정한다.
- Exploitation : 대부분의 경우, 현재 상태에서 이동할 수 있는 상태 중 가장 높은 가치를 가지고 있는 상태가 되도록 탐욕적으로(greedily) 행동한다.
- Exploration : 간혹, 현재 상태에서 이동할 수 있는 상태 중 무작위로 하나를 골라 그 상태가 되도록 행동한다.[8]
3. 게임 결과를 바탕으로 가치 함수를 업데이트하고[9], 2번으로 돌아가 이 과정을 필요한 만큼 반복한다. 현재 상태를
이때
적(opponent)이 고정되어 있을 때
이 방식으로 학습하는 것을 TD Learning(Temporal-Difference Learning)이라 한다. TD Learning은 model-free method 중 하나이다.
RL에 대한 오해들
RL을 적용한 예시로 가장 유명한 것이 알파고이다 보니, RL에 대한 많은 오해들이 있다.
- RL은 적이 있을 때만 쓸 수 있다?
- 아니다. RL은 적이 없어도 쓸 수 있다.
- RL은 episodic task에만 쓸 수 있다?
- episodic task란 위에서 살펴 본 tic-tac-toe, 알파고가 한 바둑과 같이 끝이 있는 과제를 뜻한다. 이의 반댓말은 continuing task로, 로봇 청소기의 청소(끊임없이 오염이 진행되므로 로봇 청소기는 충전할 때를 제외하고는 계속 청소를 한다) 등이 그 예이다.
- 많은 경우 RL은 episodic task에만 쓸 수 있다고 오해하는데, RL은 continuing task에서도 쓸 수 있다.
- RL은 이산적인 상황(discrete case)에서만 쓸 수 있다?
- 아니다. RL은 연속적인 상황에서도 쓸 수 있다.
- RL은 상태 집합(state set)이 작은 경우에만 쓸 수 있다?
- 아니다. 알파고가 보여주었다시피 상태 집합이 매우 큰 경우에도 RL은 성공적으로 적용된다.
- 참고로 상태 공간이 너무 큰 경우 함수 근사(function approximation) 기술을 사용할 수 있다.
- RL은 사전 지식(prior knowledge)과 함께 쓸 수 없다?
- 아니다. RL은 반드시 제로베이스에서 시작하지 않아도 된다.
- RL은 상태가 명확한 경우에만 쓸 수 있다?
- 아니다. RL은 몇몇 상태가 숨겨져 있더라도 사용할 수 있다.
- RL은 행동의 결과를 예상하는 단기간 모델(short-term model)이 있어야만 쓸 수 있다?
- 아니다. 모델 없이도 동작하는(model-free method) RL이 있다.
(귀를 통해) "앉아!"라는 말을 듣고, 행동(action)을 수행하고, 그게 맞는 행동일 경우(앉기) 보상(간식)을 받는다. ↩︎
원래 피드백이라는 단어는 어떤 행동을 했을 때 그에 대한 결과로 받게 되는 값을 의미한다. Evaluative Feedback은 에이전트의 행동에 의해 에이전트를 둘러싸고 있는 환경이 그 결과로서 제공하는 값이므로, 피드백이라는 단어가 적절하다. 그러나 Instructive Feedback의 경우 행동과 관련없는 독립적인 값이므로, 피드백이라는 단어가 사실 적절치 않다. Instructive Feedback이라는 용어는 순전히 Evaluative Feedback에 대한 반댓말로서, Evaluative Feedback과 대구(對句)를 이루고자 Feedback이라는 단어를 쓴 것이다. ↩︎
이 경우 보상은 "맛있는 식사"이다. ↩︎
이 경우 보상은 "환자의 회복"이다. ↩︎
게임판의 한 칸에는 O, X, 공백(아직 아무도 놓지 않음), 이렇게 3가지 상태가 가능하므로 3×3 게임판에서 가능한 모든 경우의 수는
이 된다. 물론 이 중 상당수는 실제 게임에서 도달 불가능한 상태이기에, 이들을 전략적으로 제거하면 경우의 수를 훨씬 줄일 수 있다. ↩︎ 인공지능이 항상 X를 놓는다고 가정하자. ↩︎
아직 이길지 질지 모르므로 승률이 반반(0.5)이라 설정한 것이다. ↩︎
이렇게 움직이는 것을 exploratory move라 한다. ↩︎
이를 back-up이라 부른다. ↩︎
Comments