에이전트와 환경의 관계
이전 글에서 보았던 k-armed Bandit Problem의 경우 에이전트가 행동을 할 때마다 보상이 발생했다. 그러나 그 과정에서 에이전트를 둘러싸고 있는 환경(environment)의 상태(state)가 변하지는 않았다.
하지만 일반적인 RL 문제의 경우 에이전트가 행동을 수행하면 보상이 발생할 뿐만 아니라 환경의 상태가 변한다. 그래서 에이전트는 상태를 고려하여 다음 행동을 결정해야 한다.[1] 일반적인 RL 문제에서 에이전트는 매 시간 간격(time step)
보면 알겠지만,
MDP (Markov Decision Process)
어떤 RL 문제에서, 확률변수
사실 대부분의 RL 문제는 (Finite) MDP 문제로 환원시켜 생각할 수 있다. 연속적으로 일어나는 RL 문제의 경우 가상의 시간 단계(stage)가 있어 각 단계에서 의사결정 및 행동이 이루어진다고 생각하면 된다. 또한 대부분의 문제에서 환경과 상태를 적절히 잘 정의하면[7] Markov 속성을 가지게 할 수 있다.
Dynamics Function
상술했듯이 MDP는 바로 직전의 상태값
{:.text-align-center}
이 함수를 MDP의 Dynamics Function이라 한다(
MDP에서 Dynamics Function는 아주 중요하다. Dynamics Function만 알면 필요한 모든 것을 계산할 수 있기 때문이다.
- 상태 전이 확률(State Transition Probability)
[9] : 상태 에서 행동 를 해 상태 이 될 확률 ( )
- (상태, 행동) 쌍에 대한 보상 기댓값(expected rewards for state-action pairs)
: 상태 에서 행동 를 할 때의 보상의 기댓값 ( )
- (상태, 행동, 다음 상태) 쌍에 대한 보상 기댓값(expected rewards for state-action-next-state triples)
: 상태 에서 행동 를 해 상태 이 되었을 때의 보상의 기댓값 ( )
목표(Goal)와 보상(Reward)
RL에서 목표(goal)는 보상(reward)이라는, 환경이 에이전트에게 제공하는 일종의 시그널을 통해 구체화할 수 있다. RL의 목표는 (장기적인 관점에서) 받을 수 있는 보상의 총합을 최대화하는 것이다.[10] 이렇게 목표를 정의할 때 보상이라는 실수값을 쓰는 것은 RL만이 가진 특색이다.
즉, 만약 에이전트가 특정한 행동을 하길 원한다면 그 행동을 했을 때 적절한 보상을 주면 된다. 그러나 보상은 목표에 대한 사전 지식(prior knowledge)을 에이전트에게 알려주는 식으로 사용되어선 안된다. 조금 더 쉽게 말하자면, 보상은 반드시 최종 목표(goal)에 대해 주어저야지, 중간 목표(subgoal)에 대해 주어져선 안 된다.
예를 들어 체스 게임을 플레이하는 에이전트를 만들 때, 보상은 최종 목표인 "게임 승리"에 대해 주어져야 한다. 비록 우리는 "상대편 말을 잡는다" 또는 "보드의 중앙 영역에 대한 지배권을 갖는다"와 같은 중간 목표들이 게임을 승리하는데 필요하다는 사전 지식을 알고 있지만, 이런 중간 목표들에 대한 보상을 주면 에이전트는 최종 목표에 달성하는 방법을 찾기보단 중간 목표들을 달성하는 방법(ex. 게임에는 져도, 상대의 말을 최대한 많이 죽이는 방법)을 학습해 버릴 가능성이 높다.
보상은 에이전트에게 목표가 *무엇(what)*인지 알려주는 역할을 해야지, 목표를 어떻게(how) 달성하는지 알려주는 역할을 해선 안 된다.[11]
Return
이때까진 RL 에이전트의 목표를 장기적인 관점에서 받을 수 있는 보상의 총합을 최대화하는 것이라 정의했다. 이때 "장기적인 관점에서 받을 수 있는 보상"이란 구체적으로 무엇일까?
RL 에이전트의 목표를 엄밀하게 정의하면 Return을 최대화하는 것이라 할 수 있다. Return
Episodic Task vs. Continuing Task
RL 문제는 크게 두 가지로 분류할 수 있다.
- Episodic Task : 에이전트와 환경 간 상호작용에서, 자연스럽게 끊어지는 단위가 있는 경우
- Continuing Task : 에이전트와 환경 간 상호작용에서, 자연스럽게 끊어지는 단위 없이 연속적으로 계속 이루어지는 경우
Episodic Task
Episodic Task에서, 자연스럽게 끊어지는 상호작용의 단위를 에피소드(Episode)라 한다. 예를 들어 미로를 찾는 로봇의 경우, 매 도전이 하나의 에피소드이다. 또 바둑을 두는 에이전트의 경우, 바둑 게임 한 판 한 판이 하나의 에피소드이다.
Episodic Task의 상태는 크게 종료 상태(terminal state)와 비종료 상태(nonterminal state)로 구분할 수 있다. 각 에피소드는 비종료 상태 중 하나인 시작 상태(starting state)에서 시작해 종료 상태가 되면 끝난다. 그리고 다시 시작 상태로 돌아가 다음 에피소드가 시작된다. 이때 비종료 상태들의 집합을
각 에피소드는 다른 에피소드와 독립적이다. 예를 들어 바둑을 두는 에이전트에서, 전 에피소드에 승리했다고 바둑돌을 몇 개 더 두고 시작하는 경우는 없다. 전 에피소드의 결과와 상관없이 처음으로 돌아가 다시 독립적인 에피소드가 시작된다. 이 말을 바꿔서 말하면, Episodic Task에서 각 에피소드는 모두 같은, 하나의 종료 상태에서 끝나고, 결과에 따라 보상만 달라진다고 할 수 있다.
Episodic Task에서 Return은 각 에피소드마다 계산된다. 즉 Return의 마지막 시간 간격
Episodic Task에서 상태를 표현할 때는 조금 다른 표기법을 사용해야 한다. 이때까진 상태를
Continuing Task
Continuing Task의 예로는 R2-D2나 C-3PO와 같은 안드로이드 로봇이 있다. Continuing Task에서 Return의 마지막 시간 간격
이때 Discount되는 양을 조절하는 파라미터
Discounting은 미래에 받을 보상이 현재 얼마만큼의 가치가 있는지를 나타낸다. 시간
Discounted Return 식은 다음과 같이 점화식 형태로 변형할 수 있다.
이 성질은 다양한 RL 알고리즘에서 응용된다.
여담 : Episodic Task와 Continuing Task 합치기
Episodic Task의 Return 식과 Continuing Task의 Return 식을 통합하는 두 가지 방법이 있다.
첫 번째 방법은 Absorbing state를 이용하는 것이다. Absorbing state는 오직 자기 자신으로만 전이(transition)가 가능하고, 전이 간 받는 보상은 0인 특별한 상태를 의미한다. 이때, Episodic Task에서 한 에피소드가 종료되는 것은 Absorbing state에 진입하는 것으로 해석할 수 있다. Episodic Task에서 Absorbing state를 사용하면 무한한 상태가 있는 셈이므로
두 번째 방법은 다음 식을 이용하는 것이다.
Episodic Task일 때는
일반적으로는 표기의 편의성 때문에 위 두 가지 방법 중 하나를 선택하여 Episodic Task와 Continuing Task의 Return을 한 번에 나타낸다.
정책(policy)과 가치 함수(value function)
이전 글에서 살펴본 정책과 가치 함수를 다시 한 번 살펴보자.
정책(policy)은 에이전트가 특정 상태에서 어떤 행동을 해야 할 지 알려주는 함수로, 일반적으론 확률의 형태를 띄고 있다. 즉 정책
한편 가치 함수(value function)에는 두 가지 종류가 있다.
- 정책
에 대한 상태-가치 함수(state-value function for policy ) : 정책 를 따를 때, 상태 에서 예상되는 Return을 반환하는 함수
- 정책
에 대한 행동-가치 함수(action-value function for policy ) : 상태 에서 행동 를 하고 그 이후에는 정책 를 따를 때 예상되는 Return을 반환하는 함수
위 식을 보면 알겠지만, 상태-가치 함수와 행동-가치 함수는 모두 정책에 따라 바뀐다. 왜냐하면 Return은 에이전트가 미래에 어떤 행동을 할지에 따라 달라지고, 에이전트는 정책에 따라 행동을 결정하기 때문이다. 또한 만약 상태
MDP의 경우 위 문단에서 정의한 Return 식을 이용해, 모든 상태
거의 대부분의 RL 알고리즘에서는 가치 함수를 추정하는 단계가 있다. 가치 함수는 경험(experience)을 바탕으로 추정 가능하다. 예를 들어, MC(Monte Carlo) Method라 부르는 가치 함수 추정 기법은 여러 번의 시뮬레이션을 수행해 받은 Return들의 평균값을 가치로 사용한다. FA(Function Approximation)라 부르는 가치 함수 추정 기법은 가치 함수를 여러 개의 파라미터를 가진 함수(parameterized function)로 설정하고,[14] 여러 번의 시뮬레이션을 통해 이 파리미터를 학습시킨다. FA는 상태의 수가 너무 많아 MC Method를 쓰기 힘든 경우에 자주 사용된다. 두 방법 모두 시뮬레이션 횟수가 많아질수록 추정값이 점점 정확해진다.
Bellman Equation : 가치 함수의 재귀성
위 문단에서 살펴본 Return의 재귀성을 다시 보자.
이를 상태-가치 함수
이 식을
특정 상태
의 가치 는, 도달 가능한 모든 다음 상태 에서의 ( 만큼 Discounted 된) 가치 와 그 상태가 될 때 받을 수 있는 보상 을 더한 값들에, 해당 상태가 될 확률을 곱한 가중평균(weighted average)과 같다.
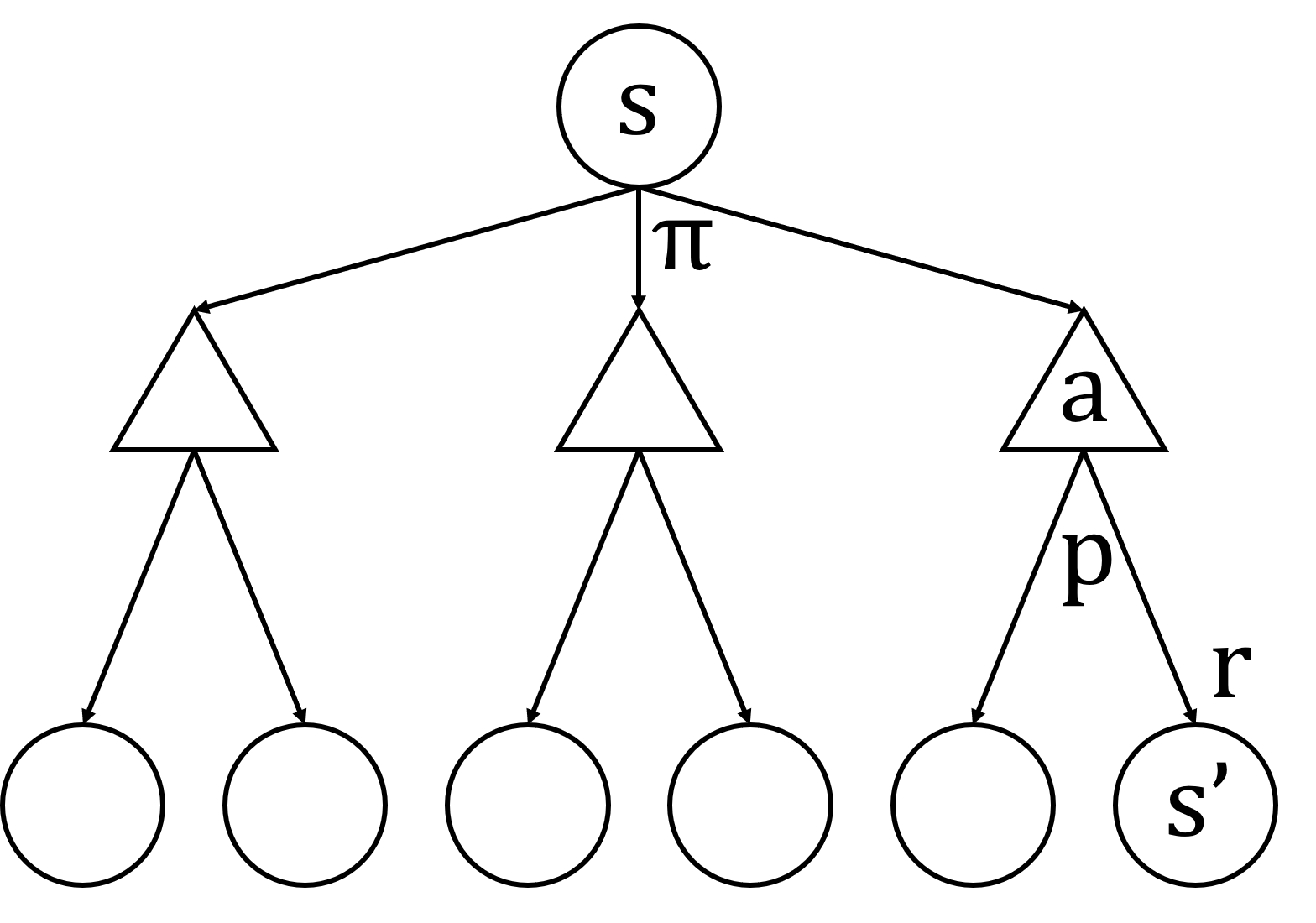
Fig.01
원은 상태를, 삼각형은 행동을 나타낸다. 상태
Bellman Equation을 이용하면 마지막 상태로부터 계속 위로 올라가면서 각 상태들의 가치를 구할 수 있다. 이런 식으로 위로 올라가며 연산하는 것을 Backup Operation이라 하고, Fig.01과 같이 Backup Operation이 적용될 수 있는 그림을 Backup Diagram이라 한다. 참고로 Backup Operation은 RL에서 매우 자주 사용되는 연산 형태 중 하나이다.
마찬가지로, 행동-가치 함수
최적 정책(Optimal Policy)과 최적 가치 함수(Optimal Value Function)
RL 문제를 푼다는 것은 쉽게 말해 장기적인 관점에서 가장 많은 보상을 받을 수 있는 정책을 찾는 것이다.
정책
이때, 다른 정책보다 좋거나 같은 정책이 반드시 하나 이상 존재한다. 이 정책을 최적 정책(optimal policy)
Bellman Optimality Equation
최적 가치 함수도 가치 함수의 일종이기에 위 문단에서 살펴본 Bellman Equation을 적용할 수 있다.
위 두 식을 각각 Bellman (optimality) equation for
Finite MDP에서는 Bellman optimality equation for
Gridworld
5×5 게임판에 말이 하나 놓여 있다. 말은 다음과 같이 환경과 상호작용할 수 있다.
- 환경의 상태는 현재 게임판에서 말이 있는 칸(cell)의 위치로 주어진다.
- 각 칸에서 말은
north,south,west,east, 네 가지 행동 중 하나를 수행할 수 있다. 각 행동을 하면 해당 방향으로 1칸 움직인다. - 만약 말의 행동이 말을 게임판 밖으로 나가게 하면, 말을 움직이지 않고 -1의 보상을 받는다.
- 만약 말이 A 위치에 놓여있다면, 어떠한 행동을 수행하던지 A' 위치로 이동하게 되고 보상 +10을 받는다.
- 만약 말이 B 위치에 놓여있다면, 어떠한 행동을 수행하던지 B' 위치로 이동하게 되고 보상 +5를 받는다.
- 위 세 가지 경우를 제외한 나머지 모든 경우에서는 보상 0을 받는다.
이 문제에 대해
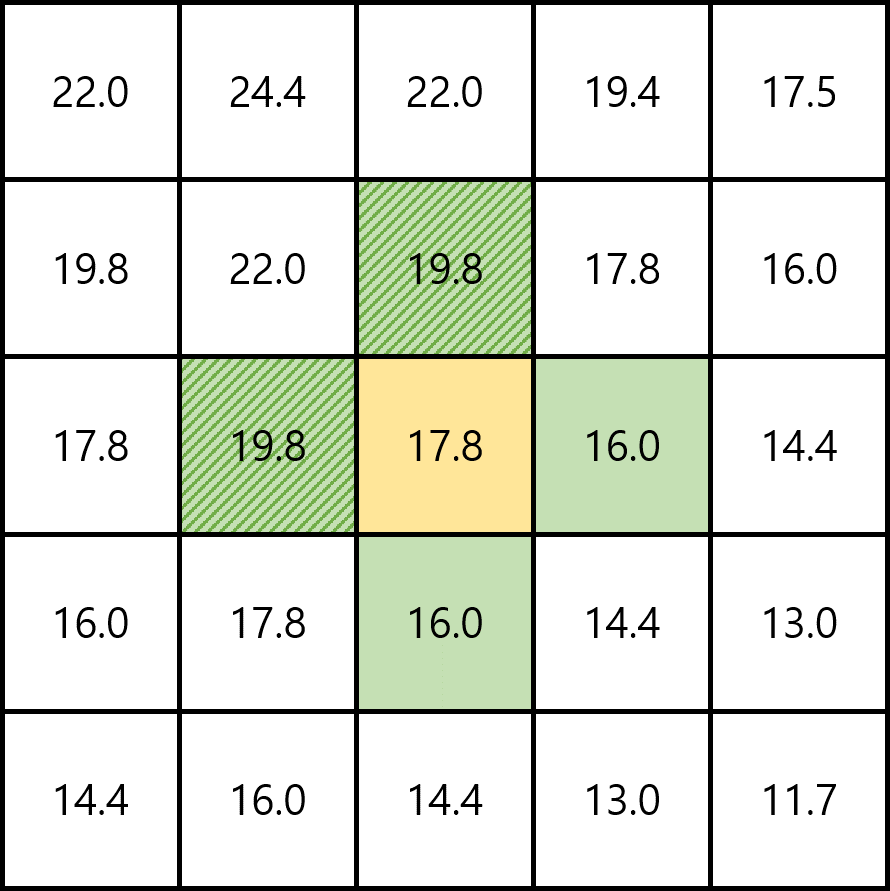
Fig.02
이때, 가운데 칸(노란색)에서의 최적 정책을 구해보자. 가운데 칸에서 north, south, west, east, 각 행동들을 했을 때 전이할 수 있는 칸들은 초록색으로 표시된 칸들이다. 이들 중 가장 큰 Return 기댓값을 가지는 상태는 north 행동을 취해 전이할 수 있는 위 칸 상태와 west 행동을 취해 전이할 수 있는 왼쪽 칸 상태이다(빗금친 초록색 칸). 즉 최적 정책은 가운데 칸에 대해 north, west에 0이 아닌 확률을 배정하고 south, east에 확률 0을 배정해야 한다.
참고로 주어진
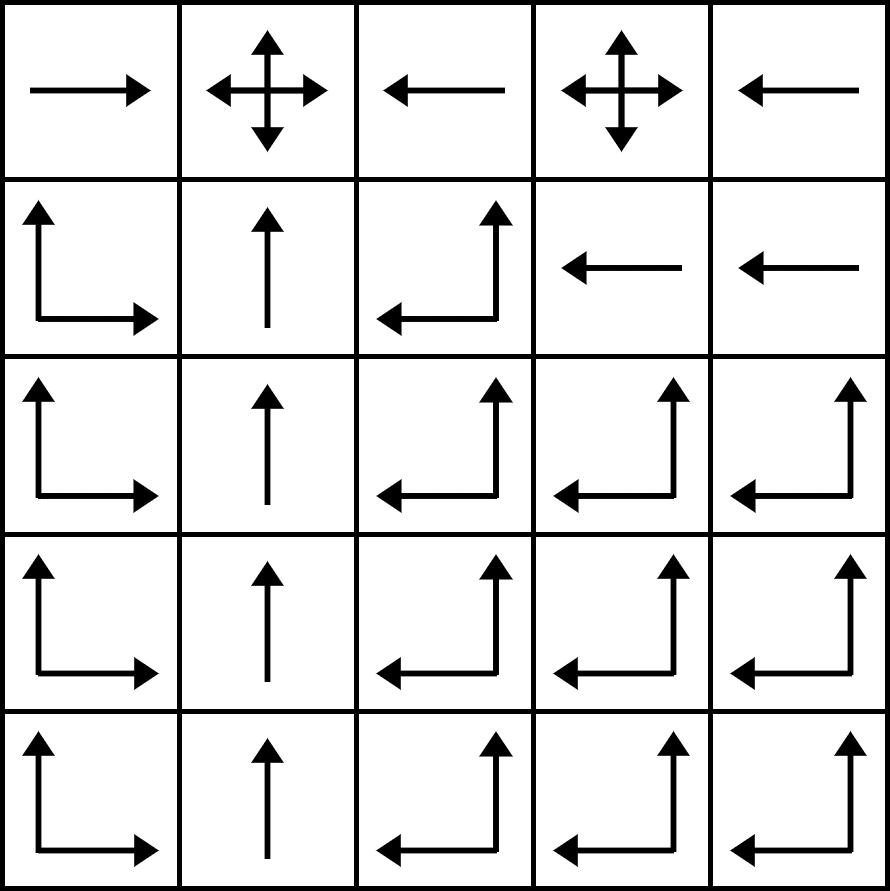
Fig.03
각 칸에서의 화살표는 0이 아닌 확률(nonzero probability)을 의미한다(화살표가 없는 방향으로는 확률이 0이다).
여담 : Bellman optimality equation 풀이의 어려움
이처럼 Bellman optimality equation을 풀면 최적 정책을 알 수 있고, 따라서 RL 문제를 해결할 수 있다. 하지만 일반적으로는 RL 문제를 풀기 위해 Bellman optimality equation을 직접 풀진 않는다. 그 이유는 다음과 같다.
- 일반적으로는 RL 문제의 Dynamics Function을 알 수 없다.
- Markov 속성이 성립하지 않을 수 있다.
- 만약 위 두 조건이 성립해도, 상태의 수가 너무 많다면 Bellman optimality equation이 계산 불가능해지거나(computational limitation), 심지어 가치, 보상 등을 저장할 저장공간이 부족할 수도 있다(memory limitation).
따라서 많은 RL 풀이법들은 Bellman optimality equation을 직접 풀기보단 이를 근사(approximation)하는 방식을 취한다.
k-armed Bandit Problem에서는
, , …일 때 선택할 수 있는 행동의 종류가 모두 같았다(항상 개의 옵션 중 하나를 선택할 수 있었다). 즉 k-armed Bandit Problem의 경우 행동을 선택할 때 아무런 값도 고려할 필요가 없었다(이전 보상을 바탕으로 다음 행동을 선택하는 것은 '보상을 최대화한다'는 목적을 위해서였지, 무슨 제약사항이 있어서 한 것은 아니었다). 그러나 일반적인 RL 문제의 경우 환경의 상태에 따라 특정 행동은 선택 불가능해질 수도 있다(= 상태는 선택 가능한 행동의 집합을 결정한다). 그래서 선택 가능한 행동의 집합을 과 같이 상태( )에 대한 함수 형태로 표기한다. ↩︎ 이 글에서 시간 간격을 이산적으로(discrete) 놓은 이유는 논의를 단순화하기 위함이다. 당연히 RL에서는 이산적인 시간뿐만 아니라 연속적인 시간도 다룬다. 참고로 연속적인 시간에서의 RL 문제에도 이산적인 시간에서의 RL을 다룰 때의 아이디어를 확장해 사용할 수 있는 경우가 많다. ↩︎
만약 모든 상태에서 선택할 수 있는 행동의 집합이 동일하다면(즉
가 항등함수이면) 단순히 라 쓰기도 한다. ↩︎ 행동
의 결과가 과 임에 주목하라. 시간 에서의 행동의 결과가 시간 에서의 보상과 상태로 나온다. 이 표기법을 사용하면 보상과 상태가 상호 결정적인(jointly determined) 값임을 강조할 수 있기에 많이 사용된다. ↩︎ 보상
과 상태 의 순서는 바뀌어도 된다. ↩︎ 즉, 과거의 상태(
, , …) 및 행동( , , …)에는 영향을 받지 않고, 오직 바로 직전 상태( ) 및 행동( )에만 영향을 받는다는 것이다. ↩︎ RL에서 환경은 "에이전트의 외부"라 정의된다. 이때 에이전트와 환경의 경계를 어디까지로 봐야 할까? 일단 이 경계는 물리적 경계와 다를 수 있다. 예를 들어 물컵의 위치, 모양 등을 인식하는 센서와 로봇 팔을 움직이는 모터로 구성된, 물컵을 들어올리는 로봇 팔을 생각해 보자. 물리적으로야 센서와 모터는 하나의 몸이지만, RL의 관점에서는 보통 모터를 에이전트로, 센서는 환경의 일부라 본다. 사실 이 문제에 명확한 정답은 없지만, 일반적으로는 에이전트가 마음대로 조작할 수 없는 영역을 에이전트의 외부, 즉 환경이라 본다. 이때 주의해야 할 것이, 에이전트와 환경의 경계는 에이전트가 완전히 통제(absolute control)할 수 있는 영역에 대한 경계이지, 에이전트의 지식(knowledge)에 대한 경계가 아니다. 에이전트는 환경이 어떻게 동작하는지에 대한 지식(ex. 보상은 어떻게 계산되는지 등)을 알고 있을 수도 있다(원하는 대로 통제할 수는 없지만 말이다). ↩︎
보면 알겠지만
에는 오직 일 때의 상태/행동 항만 있지, , , …일 때의 상태/행동 항은 없다(Markov 속성). ↩︎ 원래
는 Dynamics Function을 의미하는 기호이지만, 상태 전이 확률을 나타내는 기호로도 혼용된다. ↩︎ 이를 보상 가정(Reward Hypothesis)이라 한다. ↩︎
사전 지식은 초기 정책(initial policy) 또는 가치 함수(value function)을 통해 전달해야 한다. ↩︎
는 0부터 시작한다. ↩︎ 최대값이 정해져 있는 경우(정확히는, 상한이 있는 경우) ↩︎
파라미터의 수는 상태의 수보다 작다. ↩︎
둘을 합쳐서 한 번에 Bellman optimality equation이라 부른다. ↩︎
정확히는, 최고의 행동을 해 도달하는 상태에서의 가치에 Discount를 적용한 값과 해당 행동을 함으로서 받은 보상을 더한 값에, 해당 행동이 일어날 확률을 곱한 값과 같다. ↩︎
즉, 최대 Return 기댓값을 가지지 않은 상태로 전이하는 행동들에는 0의 확률을 배정한다. ↩︎
최적 정책을 구하려면 특정 상태에서 각 행동으로 전이 가능한 바로 직후 상태의 Return 기댓값만 비교하면 된다. 1차 탐색이란 말의 뜻은 이렇게 (더 이후를 볼 필요 없이) 깊이가 1인 탐색을 하면 된다는 뜻이다. ↩︎
컴퓨터 공학에서 탐욕적(greedy)이란 말은 당장 눈 앞에 좋아보이는 선택을 하는 것을 의미한다. 최적 정책을 구하려면 특정 상태에서 각 행동으로 전이 가능한 바로 직후 상태의 Return 기댓값만 비교하면 된다. 탐욕적이란 말은 이렇게 (더 이후를 볼 필요 없이) 당장 눈 앞에 좋아보이는 행동을 선택한다는 뜻이다. ↩︎
가 일종의 캐시(cache) 역할을 한다고 이해하면 된다. ↩︎
Comments