다음과 같은 에피소드를 관측했다고 해 보자.
이때 상태
MC Method에서는 시점
(단,
한편, 1-step TD Method(= TD(0) Method)에서는 시점
그렇다면 MC Method와 1-step TD Method 중간에 있는 방법도 있을 것이다. 그러니까, 시점
이 방법을
에서 빨간색 테두리 영역을
오류 감소 속성(The Error Reduction Property)
가 성립한다.
Pseudo Code :
// 아래 의사 코드에서,
// ex)
입력 : 정책
모든
Loop for each episode:
Loop for
If
현재 상태
If
If
If
until
예제 : Random Walk
이전 글에서 보았던 Random Walk 문제에서 첫 번째 에피소드로 다음과 같은 에피소드를 얻었다고 해 보자.
C, 0, D, 0, E, 1, T
1-step TD Method에선 이 경우
그렇다면
Random Walk (Updated)
Fig.01과 같은 게임판 위에서, 말은 다음과 같은 규칙으로 움직인다.
- S1 ~ S19, 이렇게 총 19개의 상태가 존재한다. 모든 에피소드는 가운데 S10에서 시작한다.
- 각 상태에서는 각각 50% 확률로 왼쪽 혹은 오른쪽으로 이동할 수 있다.
- 가장 왼쪽 끝으로 가면 -1의 보상을 받는다. 가장 오른쪽 끝으로 가면 +1의 보상을 받는다. 이외의 모든 이동은 0의 보상을 받는다.

Fig.01 Random Walk (Updated)
Code : Random Walk (Updated)
import numpy as np
import matplotlib.pyplot as plt
def generateEpisodes(episode_num, state_num=19):
episodes = []
for e in range(episode_num):
episode = []
S = state_num // 2
episode.append(S)
status = True
while status:
delta = np.random.choice([-1, 1])
if S == 0 and delta == -1:
R = -1
S = state_num
status = False
elif S == state_num - 1 and delta == 1:
R = 1
S = state_num
status = False
else:
R = 0
S += delta
episode.append(R)
episode.append(S)
episodes.append(episode)
return episodes
class NStepTDPredictor:
def __init__(self, n, alpha, gamma=1, state_num=19):
self.n = n
self.alpha = alpha
self.gamma = gamma
self.state_num = state_num
self.V = self.V = np.zeros(self.state_num + 1)
self.true_values = np.array([(-1 + 2 * i / (self.state_num + 1)) for i in range(1, self.state_num + 1)])
def getRMSError(self):
return np.sqrt(np.mean(np.square(self.V[:-1] - self.true_values)))
def learn(self, episodes):
for episode in episodes:
S = [None for x in range(self.n + 1)]
R = [None for x in range(self.n + 1)]
e = 0
S[0] = episode[e]
e += 1
T = float("inf")
t = 0
while True:
if t < T:
R[(t + 1) % (self.n + 1)] = episode[e]
S[(t + 1) % (self.n + 1)] = episode[e + 1]
e += 2
if S[(t + 1) % (self.n + 1)] == self.state_num: # is terminal state?
T = t + 1
tau = t - self.n + 1
if tau >= 0:
G = sum([((self.gamma ** (i - tau - 1)) * R[i % (self.n + 1)]) for i in range(tau + 1, min(tau + self.n, T) + 1)])
if tau + self.n < T:
G += (self.gamma ** self.n) * self.V[S[(tau + self.n) % (self.n + 1)]]
self.V[S[tau % (self.n + 1)]] = self.V[S[tau % (self.n + 1)]] + self.alpha * (G - self.V[S[tau % (self.n + 1)]])
if tau == T - 1:
break
t += 1
return self.getRMSError()
def drawGraph(ns, alphas, results):
for n_idx, n in enumerate(ns):
plt.plot(alphas, results[n_idx], label=f"n = {n}")
plt.title("Random Walk (Updated)")
plt.xlabel("α")
plt.ylabel("RMS Error")
plt.xticks([0, 0.2, 0.4, 0.6, 0.8, 1])
plt.ylim(0.1, 0.6)
plt.legend()
plt.show()
if __name__ == "__main__":
repeats = 100
episode_num = 10
ns = [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
alphas = [(i / 20) for i in range(21)]
results = np.zeros((len(ns), len(alphas)))
for repeat in range(repeats):
episodes = generateEpisodes(episode_num=episode_num)
for n_idx, n in enumerate(ns):
rms_errors_by_alpha = [NStepTDPredictor(n=n, alpha=alpha).learn(episodes) for alpha in alphas]
results[n_idx] += rms_errors_by_alpha
results /= repeats
drawGraph(ns, alphas, results)코드 설명
- line 4 ~ 31 :
generateEpisodes()함수- 인자로 받은
episode_num개만큼의 에피소드를 생성하는 함수 state_num매개변수는 상태의 수를 나타냄
- 인자로 받은
- line 33 ~ 77 :
NStepTDPredictor클래스- line 34 ~ 41 :
NStepTDPredictor.__init__()메소드- line 40 : 가치 함수
self.V를 0으로 초기화한다. 종료상태(T) 때문에self.V의 크기는self.state_num + 1이 된다. - line 41 : 가치 함수의 참값(
)을 저장하는 배열 self.true_values를 만든다. 참고로 상태의 개수가개 있는 Random Walk(Updated)에서 최적 가치 함수 는 다음과 같이 계산된다: ( ).
- line 40 : 가치 함수
- line 43 ~ 44 :
NStepTDPredictor.getRMSError()메소드- 현재 가치 추정값
self.V의 RMS Error를 구하는 메소드 self.V와self.true_values의 차를 구한 후, 이를 제곱하고, 평균내고, 루트를 씌운 값이다.
- 현재 가치 추정값
- line 46 ~ 77 :
NStepTDPredictor.learn()메소드- 인자로 전달받은 에피소드들을 가지고 학습을 진행하는 메소드
- 학습 결과 만들어진
self.V에 대해 RMS Error를 계산한 결과값(self.getRMSError())을 반환한다.
- line 34 ~ 41 :
- line 79 ~ 89 :
drawGraph()함수- Fig.02를 그리는 함수
- line 91 ~ 105 : main
- 각
에 대해, 에 따라 RMS Error를 계산한 후 그래프(Fig.02)를 그린다.
- 각
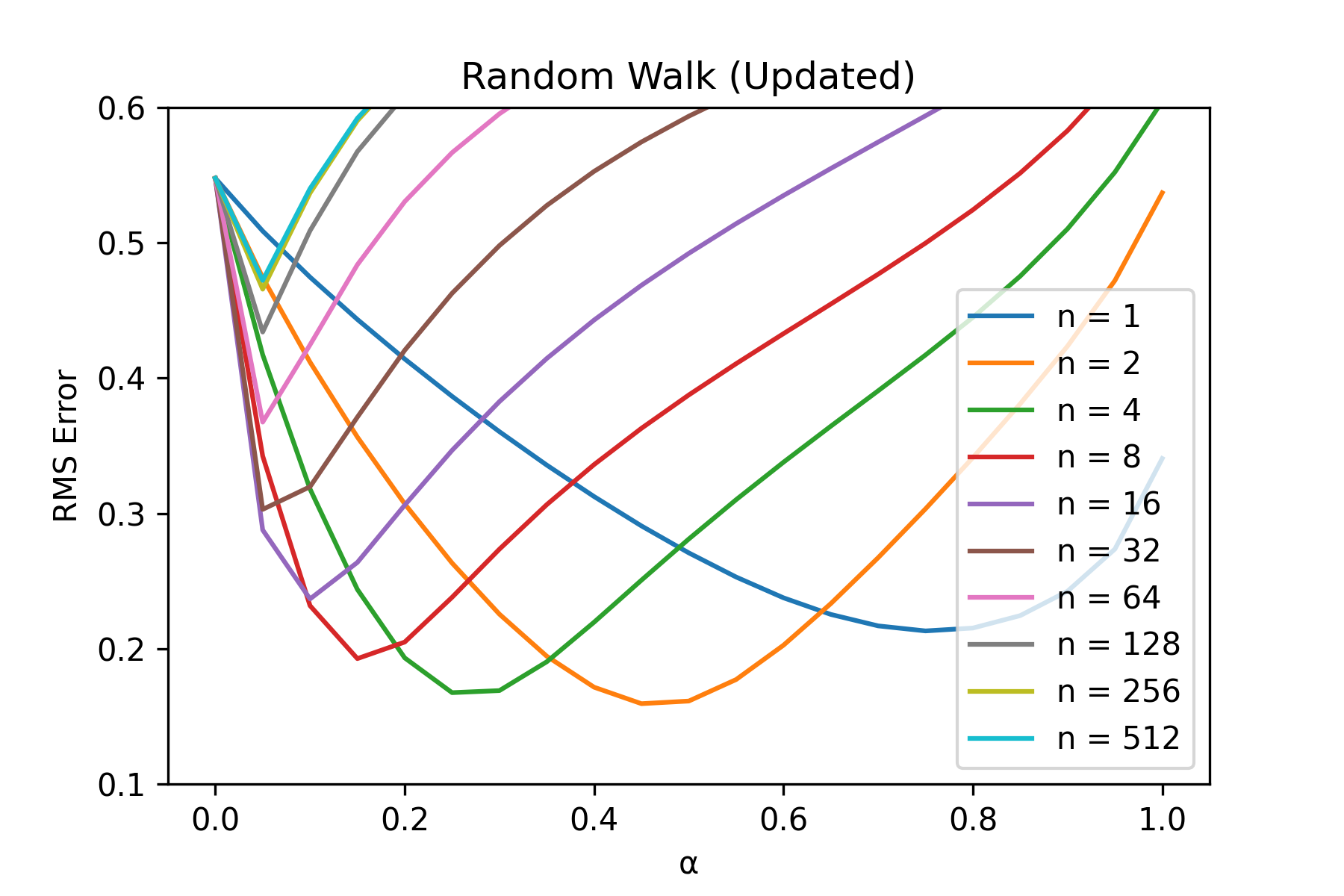
Fig.02 Random Walk (Updated) 학습 결과
적당한
위 그래프에서 볼 수 있듯이 적당한
On-policy Learning
On-policy
이전 글에서 살펴본 SARSA와
SARSA에서는 행동-가치 함수(action-value function)를 사용하므로,
이를 이용해 업데이트 식을 다음과 같이 만들 수 있다.
Pseudo Code : On-policy
// 아래 의사 코드에서,
// ex)
모든
Loop for each episode:
현재
Loop for
If
If
else:
현재
If
If
until
On-policy
이전 글에서 살펴본 Expected SARSA와
Pseudo Code : On-policy
// 아래 의사 코드에서,
// ex)
모든
Loop for each episode:
현재
Loop for
If
If
else:
현재
If
If
until
Off-policy Learning
Importance-sampling ratio
Off-policy Learning은 학습이 진행되는 목표 정책(target policy)
Importance-sampling ratio를 이용해 업데이트 식을 세우면 다음과 같이 된다.
Off-policy
Importance-sampling ratio를 이용해 다음과 같은 업데이트 식을 세울 수 있다.[7]
이 업데이트 식에서 사용하는
이 업데이트 식을 이용하면 다음과 같이 Off-policy 버전의
Pseudo Code : Off-policy
// 아래 의사 코드에서,
// ex)
모든
Loop for each episode:
Loop for
If
If
else:
If
$\rho \leftarrow \prod _{i=\tau + 1} ^{\min(\tau+n,,T-1)}\frac{\pi(A_i,|,S_i)}{b(A_i,|,S_i)}
If
until
Off-policy
Importance-sampling ratio를 이용해 다음과 같이 Off-policy 버전의
이 업데이트 식에서 사용하는
Pseudo Code : Off-policy
// 아래 의사 코드에서,
// ex)
모든
Loop for each episode:
Loop for
If
If
else:
If
$\rho \leftarrow \prod _{i=\tau + 1} ^{\min(\tau+n-1,,T-1)}\frac{\pi(A_i,|,S_i)}{b(A_i,|,S_i)}
If
until
이전 글에서 봤던 Q-Learning과 Expected SARSA는 Importance Sampling을 사용하지 않고도 Off-policy Learning을 수행했다. 그렇다면 Importance Sampling을 사용하지 않는 Off-policy
한편, Expected SARSA의 Return을 구하는 과정을 생각해보자. (1-step) Expected SARSA Return은 다음 상태
이 두 질문에 대한 답이 바로
이렇게 계산한
Pseudo Code :
// 아래 의사 코드에서,
// ex)
모든
Loop for each episode:
Loop for
If
If
else:
If
If
else:
Loop for
until
는 미래에 받을 보상들( , , …, )에 대한 프록시(proxy) 역할을 한다. ↩︎ 는 시점 이후 미래에 받을 보상들( , , …, )에 대한 프록시(proxy) 역할을 한다. ↩︎ 엄밀히 말하면,
일 때 ↩︎ 여기서 아래 첨자
은 시점 부터 까지 개의 보상을 사용함을 의미한다. ↩︎ 일 때의 식은 시점 이후의 보상 항들과 가치 추정값 을 모두 0이라 놓고 계산한 것이라 기억하면 편하다. ↩︎ 그래서
-step TD Method에서 업데이트의 목표로 사용하는 것이다. ↩︎ 여기서의
은 On-policy -step SARSA에서 정의한 버전을 사용한다. ↩︎ 여기서의
은 On-policy -step Expected SARSA에서 정의한 버전을 사용한다. ↩︎
Comments