모델(Model)
모델(Model) 은 상태(state)와 행동(action)을 입력으로 받아 다음 상태와 보상(reward)을 출력하는 일종의 함수다. 에이전트(agent)는 특정 상태에서 환경(environment)이 특정 행동에 어떻게 반응할 지 예측하기 위해 모델을 사용한다.
모델은 크게 두 종류로 구분할 수 있다.
- Distribution Model : 가능한 모든 결과값들과 그 결과값이 나올 수 있는 확률을 출력하는 모델
- Sample Model : 해당 결과값이 나올 수 있는 확률에 따라 한 개의 결과(샘플)를 임의로 출력하는 모델
예를 들어 주사위를 굴리는 문제에 대해 모델을 만든다면, Sample Model의 경우 1, 2, 3, 4, 5, 6 중 랜덤하게 하나의 숫자를 출력하게 된다.[1] 그리고 Distribution Model의 경우 [(1, (1/6)), (2, (1/6)), (3, (1/6)), (4, (1/6)), (5, (1/6)), (6, (1/6))]과 같이, 나올 수 있는 모든 결과값들과 그 결과값이 나올 확률을 출력하게 된다.
Distribution Model이 있다면 이를 이용해 결과 샘플을 만들 수 있으므로, Distribution Model이 Sample Model보다 더 강력한 모델이다. 그러나 일반적으로 Distribution Model은 Sample Model에 비해 만들기 어렵다.
모델을 이용하면 가짜 경험(simulated experience)을 만들 수 있다. 시작 상태와 행동이 주어졌을 때, Sample Model을 이용하면 완전한 샘플 에피소드 하나를 만들어낼 수 있고, Distribution Model을 이용하면 가능한 모든 에피소드들을 각 에피소드가 발생할 확률과 함께 만들어낼 수 있다.
모델 기반 방법(Model-based Method) vs. Model-free Method
모델을 사용하는지 안하는지를 가지고 RL을 분류할 수 있다.
- 모델 기반 방법(Model-based Method) : 모델을 이용해 학습을 진행하는 RL 학습법
- Model-free Method : 모델을 이용하지 않고 학습을 진행하는 RL 학습법
모델 기반 방법의 예로는 DP가 있다. DP에서는 환경에 대해 모든 지식이 주어진 경우를 가정했는데, Distribution Model이 주어졌다면 DP를 적용할 수 있다. Model-free Method의 예로는 MC Method, TD Method가 있다.
Planning
Planning이란 모델이 생성한 가짜 경험(simulated experience)을 이용해 상태 공간(state space)에서 가치 함수(value function)를 계산해 가며 최적 정책(optimal policy)을 만드는 모든 종류의 방법을 의미한다.[2]
사실 Planning은 거창하게 새로운 것이 아니다. 우리가 이전에 봤던 MC Method, TD Method와 같은 Model-free Method에서는 환경과 실제로 상호작용하면서 만든 실제 경험(real experience)을 토대로 학습이 진행되었는데, Planning은 모델이 생성한 가짜 경험(simulated experience)에 대해 동일한 알고리즘을 적용하는 것이다.[3] 예를 들어 다음과 같이 모델이 생성한 가짜 경험에 대해 Q-Learning을 적용하는, Q-Planning을 생각할 수 있다.
Pseudo Code : Random-sample Q-Planning
Loop forever:
상태
모델을 이용해 상태
Q-Learning 알고리즘을 적용한다 :
Dyna
위에서 살펴본 Q-Planning은 Offline 상황에서 오직 주어진 모델과 Planning만을 이용해 에이전트를 학습시키는 방법이었다. 그렇다면 Online 상황에서는 어떻게 될까? 그러니까, 환경과 상호작용하면서 계속 새로운 정보를 얻는 상황에서는 어떻게 Planning을 해야 할까?
Dyna는 Online 상황에서 사용할 수 있는, Planning, 행동(acting), 학습(Learning)이 결합된 RL 방법이다. Dyna 에이전트는 환경과 상호작용하며 실제 경험(real experience)을 얻고, 두 가지 방법으로 이를 사용한다.
- 실제 경험을 바로 사용해 (MC Method, TD Method 등의 방법을 이용하여) 가치 함수를 계산하고 정책을 개선한다. 이를 Direct RL이라 한다.
- 실제 경험을 이용하여 모델을 학습시키고[4], 이렇게 학습된 모델을 이용해 Planning을 수행한다(= 모델이 생성한 가짜 경험(simulated experience)을 사용해[5] 가치 함수를 계산하고 정책을 개선한다). 이를 Indirect RL이라 한다.
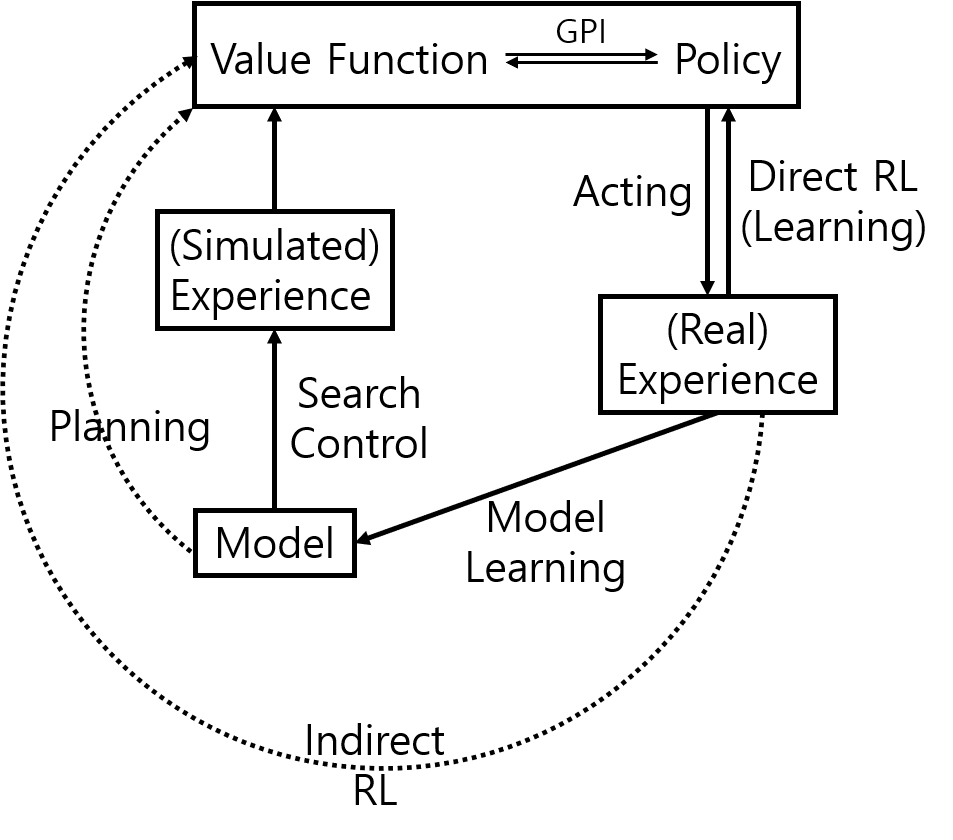
Fig.01 Dyna
Dyna는 Online 상황에서 사용할 수 있는, Planning, 행동(acting), 학습(Learning)을 결합한 RL 방법이다.
Indirect RL은 주어진 (실제) 경험을 극한까지 사용하는 방법이다. 따라서 Indirect RL을 수행하면 적은 수의 경험으로도(= 실제 환경과 최소한의 상호작용을 하고도) 에이전트를 학습시킬 수 있다. 한편 Direct RL은 훨씬 간단하고, 무엇보다 모델을 설계한 방법에 따라 발생할 수 있는 편향(bias)이 없다는 장점이 있다.
Dyna-Q는 Q-Learning으로 Direct RL을 수행하고, Q-Planning으로 Indirect RL을 수행하는 알고리즘이다.[6] 이를 의사 코드로 나타내면 다음과 같다.[7]
Pseudo Code : Dyna-Q
모든
모든
//
// (정확히는, 받을 것으로 예상되는) 보상과 다음 상태를 반환한다.
Loop forever:
현재
Loop repeat
예제 : Maze
다음 예제를 살펴보자.
Maze
Fig.02와 같은 미로가 주어졌다고 해 보자. 미로에서 에이전트는 다음과 같이 움직인다.
- 에피소드는 S에서 시작한다.
- 각 칸에서 에이전트는 상, 하, 좌, 우, 4방향으로 한 칸씩 움직일 수 있다. 단, 장애물(검은 칸) 또는 미로 바깥으로는 이동할 수 없다.
- G로의 이동은 +1의 보상을 받는다. 이를 제외한 모든 이동은 0의 보상을 받는다.
- 에이전트가 G에 도달하면 다시 S로 이동해 새로운 에피소드를 시작한다.

Fig.02 Maze
S에서 시작해, G에 도달하는 것이 목표이다. 에이전트가 G에 도달하면 다시 S로 이동해 새로운 에피소드를 시작한다. 각 칸에서 에이전트는 상, 하, 좌, 우, 4방향으로 한 칸씩 움직일 수 있다. 단, 장애물(검은 칸) 또는 미로 바깥으로는 이동할 수 없다. G로의 이동은 +1의 보상을 받는다. 이를 제외한 모든 이동은 0의 보상을 받는다.
Dyna-Q를 이용해 Maze를 푸는 에이전트를 학습시켜 보자.
Code : Maze
import numpy as np
import matplotlib.pyplot as plt
class Env:
def __init__(self):
self.board = np.zeros((6, 9))
self.board[1:4, 2] = -1
self.board[4, 5] = -1
self.board[0:3, 7] = -1
self.state = [2, 0]
def _getStateIdx(self):
return self.state[0] * 9 + self.state[1]
def initEpisode(self):
self.state = [2, 0]
return True, self._getStateIdx(), 0
def interact(self, action):
if action == 0: # up
new_state = [self.state[0] - 1, self.state[1]]
elif action == 1: # down
new_state = [self.state[0] + 1, self.state[1]]
elif action == 2: # left
new_state = [self.state[0], self.state[1] - 1]
elif action == 3: # right
new_state = [self.state[0], self.state[1] + 1]
else:
raise Exception("Invalid param:action")
if (new_state[0] < 0 or new_state[0] > 5 or new_state[1] < 0 or new_state[1] > 8) or (self.board[tuple(new_state)] == -1): # border
new_state = self.state
R = 0
status = True
elif new_state == [0, 8]: # goal
R = 1
status = False
else:
R = 0
status = True
self.state = new_state
return status, self._getStateIdx(), R
class DynaQ:
class Model:
def __init__(self):
self.model = dict()
def add(self, state, action, reward, next_state):
if not state in self.model.keys():
self.model[state] = dict()
self.model[state][action] = [reward, next_state]
def getRandomSARS(self):
state = np.random.choice(list(self.model.keys()))
action = np.random.choice(list(self.model[state].keys()))
reward, next_state = self.model[state][action]
return state, action, reward, next_state
def __init__(self, env, planning_num, alpha=0.1, gamma=0.95, epsilon=0.1):
self.env = env
self.planning_num = planning_num
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.Q = np.zeros((54, 4))
self.model = self.Model()
def policy(self, state, greedy=False):
if greedy: # greedy
max_actions = np.argwhere(self.Q[state] == np.max(self.Q[state])).flatten()
return np.random.choice(max_actions)
else: # ε-greedy
if np.random.random() < self.epsilon: # exploration
return np.random.choice(4)
else: # exploitation
max_actions = np.argwhere(self.Q[state] == np.max(self.Q[state])).flatten()
return np.random.choice(max_actions)
def test(self, title):
def getState(idx):
return [idx // 9, idx % 9]
def generateEpisode():
episode = []
status, S, R = self.env.initEpisode()
A = self.policy(S, greedy=True)
episode.append(S)
episode.append(A)
while True:
status, S, R = self.env.interact(A)
if status == False:
break
A = self.policy(S, greedy=True)
episode.append(R)
episode.append(S)
episode.append(A)
episode.append(R)
episode.append(S)
return episode
actions = ["↑", "↓", "←", "→"]
board = [[" " for x in range(9)] for x in range(6)]
board[1][2] = "■"
board[2][2] = "■"
board[3][2] = "■"
board[4][5] = "■"
board[0][7] = "■"
board[1][7] = "■"
board[2][7] = "■"
episode = generateEpisode()
i = 0
R_sum = 0
while True:
if i + 2 > len(episode) - 1:
break
S = getState(episode[i])
A = actions[episode[i + 1]]
R_sum += episode[i + 2]
i += 3
if board[S[0]][S[1]] != " ":
raise Exception("something is wrong...")
board[S[0]][S[1]] = A
S = getState(episode[i])
board[S[0]][S[1]] = "□"
print(f"{title}")
for i in range(6):
print("|", end="")
for j in range(9):
print(board[i][j], end="|")
print()
print(f"rewards = {R_sum}")
print()
return episode
def learn(self, episode_num):
history = np.zeros(episode_num)
for e in range(episode_num):
status, S, R = self.env.initEpisode()
steps = 0
while status:
steps += 1
A = self.policy(S)
status, S_, R = self.env.interact(A)
self.Q[S, A] = self.Q[S, A] + self.alpha * (R + self.gamma * np.max(self.Q[S_]) - self.Q[S, A])
self.model.add(state=S, action=A, reward=R, next_state=S_)
S = S_
for n in range(self.planning_num):
pS, pA, pR, pS_ = self.model.getRandomSARS()
self.Q[pS, pA] = self.Q[pS, pA] + self.alpha * (pR + self.gamma * np.max(self.Q[pS_]) - self.Q[pS, pA])
history[e] = steps
return history
def drawGraph(histories, episode_num, planning_nums):
for i, planning_num in enumerate(planning_nums):
plt.plot(np.arange(episode_num - 1) + 2, histories[i, 1:], label=f"[planning_num = {planning_num}]")
plt.title("Dyna-Q")
plt.xlabel("Episodes")
plt.ylabel("Steps per episode")
plt.xticks([2, 10, 20, 30])
plt.ylim(10, 800)
plt.legend()
plt.show()
if __name__ == "__main__":
np.random.seed(0)
env = Env()
agent = DynaQ(env, planning_num=30)
agent.learn(episode_num=10)
agent.test(title="Dyna-Q [planning=30, episodes=10]")
episode_num = 30
repeats = 10
planning_nums = [0, 5, 50]
histories = np.zeros((len(planning_nums), episode_num))
for i, planning_num in enumerate(planning_nums):
for repeat in range(repeats):
agent = DynaQ(env, planning_num=planning_num)
history = agent.learn(episode_num=episode_num)
histories[i] += history
histories /= repeats
drawGraph(histories, episode_num=episode_num, planning_nums=planning_nums)코드 설명
- line 4 ~ 45 :
Env클래스- line 13 ~ 14 :
Env._getStateIdx()메소드- 현재 상태(state)를 반환
- line 16 ~ 18 :
Env.initEpisode()메소드- 에이전트를 S 위치로 옮기고 새 에피소드를 시작
status,state,reward반환status: 현재 에피소드 진행 상태.True면 에피소드가 진행 중인 상태를,False면 에피소드가 종료되었음을 나타낸다.state: 현재 상태(state) (Env._getStateIdx()메소드 이용)reward: 보상
- line 20 ~ 45 :
Env.interact()메소드- 에이전트가 환경과 상호작용하는 메소드
status,state,reward반환status: 현재 에피소드 진행 상태.True면 에피소드가 진행 중인 상태를,False면 에피소드가 종료되었음을 나타낸다.state: 현재 상태(state) (Env._getStateIdx()메소드 이용)reward: 보상
- line 13 ~ 14 :
- line 47 ~ 173 :
DynaQ클래스- line 48 ~ 61 :
DynaQ.Model클래스- DynaQ가 사용하는 모델을 나타내는 클래스
- line 52 ~ 55 :
DynaQ.Model.add()메소드- 상태
state에서 행동action을 수행했을 때, 보상reward를 받고 상태next_state로 전이했다는 정보를 모델에 저장
- 상태
- line 57 ~ 61 :
DynaQ.Model.getSARS()메소드- 기존에 경험했던 상태-행동 쌍 중 무작위로 하나를 골라 가짜 경험(simulated experience)을 생성
- 상태
state, 행동action, 그리고 이를 수행했을 때 받을(것으로 예상되는) 보상reward와 다음 상태(일 것으로 예상되는)next_state을 반환
- line 73 ~ 82 :
DynaQ.policy()메소드- 현재 상태
state를 입력받아,-greedy Policy로 다음 행동을 선택하는 메소드 greedy매개변수에 True를 주면 Greedy Policy로 동작한다(즉, 탐색(exploration)을 안한다).
- 현재 상태
- line 84 ~ 150 :
DynaQ.test()메소드- 에이전트의 학습 결과(Fig.03)를 출력하는 메소드
- line 152 ~ 173 :
DynaQ.learn()메소드- Dyna-Q 알고리즘대로 에이전트의 학습을 진행하는 메소드
- 각 에피소드마다 목표(G)에 도달하기까지 몇 번의 step이 필요했는지를 저장한 배열
history를 반환한다.
- line 48 ~ 61 :
- line 175 ~ 185 :
drawGraph()함수- Fig.04를 그리는 함수
- line 187 ~ 208 : main
- line 188 : 랜덤 시드 고정
- line 191 ~ 193 : Fig.03 출력
- Planning을 30번 수행하는 에이전트를 이용해, 10개의 에피소드로 학습시킨 결과 출력
- line 195 ~ 208 : Fig.04 출력
- Planning을 0번(= Direct RL만 수행), 5번, 50번 수행하는 에이전트를 이용해, 30개의 에피소드로 학습하는 과정을 10번 반복 실행하여, 그 결과를 평균하여 그래프로 출력
- Planning을 하든 안 하든 첫 번째 에피소드에서 G에 도달아끼까지 필요한 step의 수는 같으므로(약 2,000 step) 그래프에서 생략하였다.

Fig.03 Maze - 결과
화살표는 각 칸에서 에이전트가 선택한 행동(action)을 나타낸다.
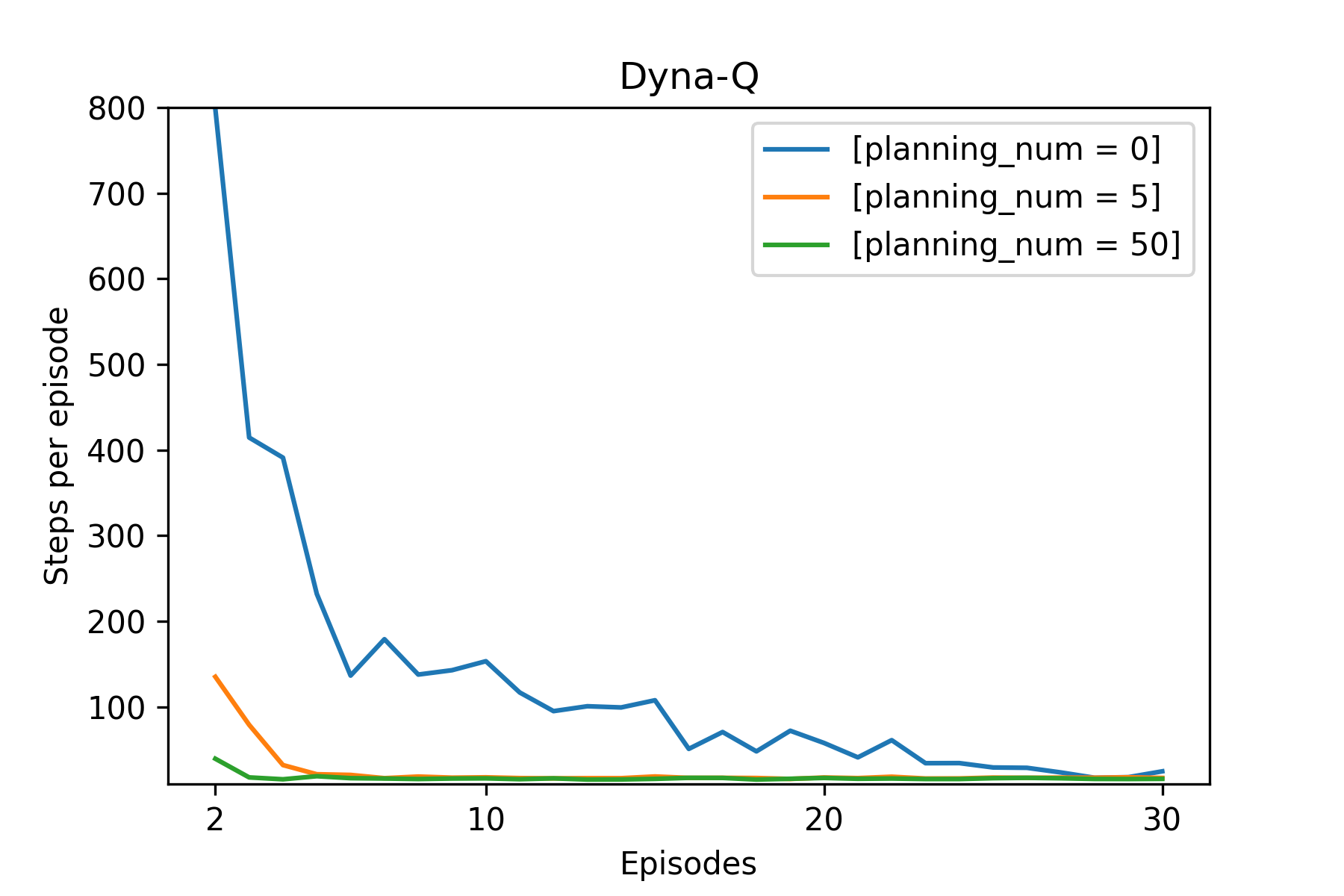
Fig.04 Maze - Planning 횟수에 따른 필요 step 수
Planning을 0번, 5번, 50번 수행하는 에이전트를 이용해, 30개의 에피소드로 학습하는 과정을 10번 반복 실행하여, 그 결과를 평균하여 그래프로 출력하였다. 첫 번째 에피소드의 결과는 생략하였다.
Fig.04에서, Planning을 많이 하는 에이전트는 Planning을 조금 하는 에이전트에 비해 적은 수의 에피소드만 가지고도 학습이 잘 되는 것을 볼 수 있다.[8] 구체적으로, 첫 번째 에피소드에서는 Planning을 하지 않는 에이전트(파란색)와 Planning을 하는 에이전트(주황색, 초록색) 모두에서 오직 한 개 상태(G)의 가치만 업데이트된다.[9] 하지만 두 번째 에피소드에서 Planning을 하지 않는 에이전트에서는 여전히 오직 한 개 상태(G 바로 직전 상태)의 가치만 업데이트되는 반면, Planning을 하는 에이전트에서는 (모델이 기억하고 있는 정보를 사용해) 여러 개의 상태의 가치가 업데이트된다.
이처럼 Planning은 에피소드 하나로 얻은 정보를 최대한 이용해 학습을 진행하는 것이기에, Planning을 사용하는 에이전트가 Planning을 사용하지 않는 에이전트보다 더 적은 수의 에피소드로도 학습이 잘 된다.
Dyna-Q+
위 Maze 예제에서, 모델이 담고 있는 정보는 항상 옳았다. 하지만 확률적인(stochastic) 환경에서 충분한 관측이 시행되지 않은 경우, 상태-행동 공간(state-action space)이 너무 커 FA(Function Approximation)를 사용하는 경우, 또는 환경이 변하는 경우 등 다양한 이유로 모델이 담고 있는 정보가 잘못될 수 있다.
예를 들어 다음과 같은 경우를 생각해 보자.
Blocking Maze
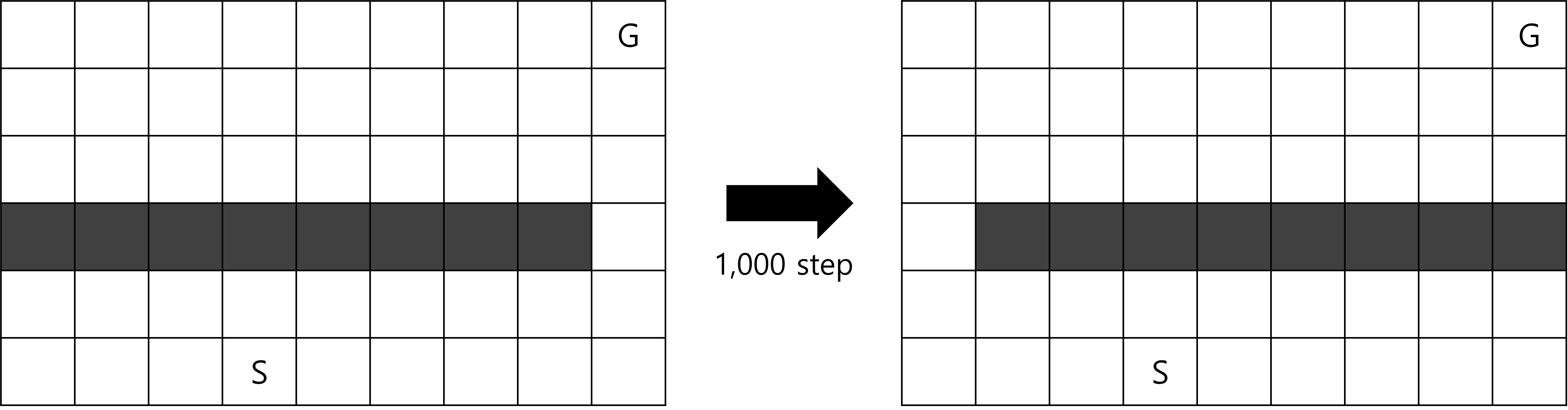
Fig.05 Blocking Maze
1,000 step이 지나면 왼쪽 미로에서 오른쪽 미로로 바뀐다.
- 처음에는 Fig.05의 왼쪽과 같은 미로가 주어진다.
- 에피소드는 S에서 시작한다.
- 각 칸에서 에이전트는 상, 하, 좌, 우, 4방향으로 한 칸씩 움직일 수 있다. 단, 장애물(검은 칸) 또는 미로 바깥으로는 이동할 수 없다.
- G로의 이동은 +1의 보상을 받는다. 이를 제외한 모든 이동은 0의 보상을 받는다.
- 에이전트가 G에 도달하면 다시 S로 이동해 새로운 에피소드를 시작한다.
- 1,000 step이 지나면 Fig.05의 오른쪽 미로로 바뀐다.
Blocking Maze에서는 1,000 step이 지나면 뚫려 있던 오른쪽 길이 막히므로, 최적 경로는 왼쪽으로 돌아가는 먼 길이 된다. 이 문제를 Dyna-Q를 이용해 푼다고 생각해 보자. Dyna-Q는 최적 경로를 찾긴 할 것이나, 오른쪽 길이 막혔다는 정보가 모델에 업데이트되고 행동-가치 함수(action-value function)
또 다른 경우를 생각해 보자.
Shortcut Maze
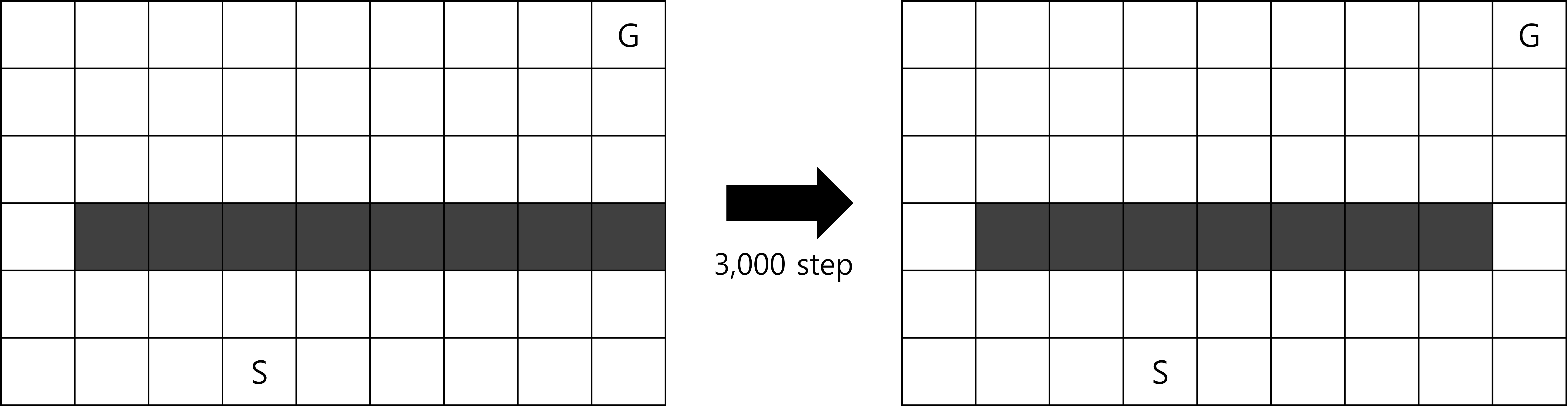
Fig.06 Shortcut Maze
3,000 step이 지나면 왼쪽 미로에서 오른쪽 미로로 바뀐다.
- 처음에는 Fig.06의 왼쪽과 같은 미로가 주어진다.
- 에피소드는 S에서 시작한다.
- 각 칸에서 에이전트는 상, 하, 좌, 우, 4방향으로 한 칸씩 움직일 수 있다. 단, 장애물(검은 칸) 또는 미로 바깥으로는 이동할 수 없다.
- G로의 이동은 +1의 보상을 받는다. 이를 제외한 모든 이동은 0의 보상을 받는다.
- 에이전트가 G에 도달하면 다시 S로 이동해 새로운 에피소드를 시작한다.
- 3,000 step이 지나면 Fig.06의 오른쪽 미로로 바뀐다.
Shortcut Maze에서는 3,000 step이 지나면 막혀 있던 오른쪽 길이 열리므로, 최적 경로는 오른쪽의 지름길을 사용하는 길이 되고, 왼쪽 길을 사용하는 기존의 경로는 차적 경로(sub-optimal path)가 된다. 이 문제를 Dyna-Q를 이용해 푼다고 생각해 보자. Blocking Maze와 같이 환경이 안 좋아 지는 경우 Dyna-Q는 시간은 좀 걸리겠지만 어쨌든 최적 경로를 찾긴 한다. 그러나 Shortcut Maze와 같이 환경이 오히려 좋아지는 경우, Dyna-Q는
위 두 가지 경우에서 볼 수 있듯이 환경이 바뀌어 모델이 가지고 있는 정보가 잘못될 경우 Dyna-Q는 잘 작동하지 않는다. 이를 해결하려면 Dyna-Q가 Exploration을 하게 하면 된다. Planning에서의 Exploration은 모델을 개선하는 과정을 의미하고, Exploitation은 현재 모델에 대해 최적의 방법대로 행동하는 과정을 의미한다. Dyna-Q 알고리즘을 잘 살펴보면, 모델에 저장된 값들을 그대로 사용해
그렇다면 Exploration을 어떻게, 얼마나 하게 해 줘야 할까? Exploration을 하지 않으면 에이전트가 환경 변화에 둔감해지게 되지만, 그렇다고 너무 많이 하면 얻을 수 있는 총 보상의 합이 줄어들게 된다.
이 문제는 사실 전형적인 Exploitation-Exploration Dilemma로, Exploration과 Exploitation의 비율을 '완벽하게' 결정하는 방법은 없다. 다만 Dyna-Q+ 라 부르는, 휴리스틱적인 해법이 있다.
Dyna-Q+의 핵심 아이디어는 오랫동안 갱신되지 않은 상태-행동 쌍에 '가중치'를 줘 에이전트가 모델이 잘못되어진 것을 빨리 발견하게 하는 것이다. 구체적으로, Dyna-Q+ 에이전트는 각 상태-행동 쌍이 마지막으로 시행된 이후 얼마나 많은 시간(time step)이 경과했는지를 추적한다. 더 많은 시간이 경과했을수록, 모델이 해당 상태-행동 쌍에 대해 기억하고 있는 결과가 잘못되어졌을 가능성이 크다. 어떤 상태-행동 쌍
위와 같이 하면
Dyna-Q+를 의사 코드로 나타내면 다음과 같다.
Pseudo Code : Dyna-Q+
모든
모든
//
// (정확히는, 받을 것으로 예상되는) 보상과 다음 상태, 그리고 해당 상태-행동 쌍을
// 마지막으로 수행한 time step을 반환한다.
Loop forever:
현재
// Model Learning
If
모든
// Planning
Loop repeat
Dyna-Q+의 의사 코드는 Dyna-Q 의사 코드와 대부분 유사하지만, 몇 가지 눈여겨봐야 하는 차이점이 있다.
- 모델에 저장하는 값이 조금 다르다. Dyna-Q+의 모델에는 보상과 다음 상태뿐만 아니라,
를 계산하기 위해 마지막으로 시행된 시간(time step)도 저장한다. - Dyna-Q와 Dyna-Q+는 Planning 과정에서 모델에 저장된 상태와 행동 중 하나를 무작위로 선택하게 되는데, Dyna-Q에서처럼 경험한 상태와 행동만 딱 모델에 저장하면 Exploration이 일어나지 않는다. 따라서 Dyna-Q+의 Model Learning 과정에서는, 상태
를 처음 경험하는 경우 모델에 만 추가하는 것이 아니라, 상태 에서 선택 가능한 나머지 모든 행동들은 시간 1에 보상 0을 받고 자기 자신( )으로 전이했다는 가짜 정보도 추가한다. 이 덕분에 Dyna-Q+에서는 좀 더 탐색적으로 새로운 행동들을 수행할 수 있게 된다.
예제 : Dyna-Q vs. Dyna-Q+ : Blocking Maze, Shortcut Maze
위에서 살펴본 Blocking Maze와 Shortcut Maze를 Dyna-Q+를 이용해 풀어보자.
Code : Dyna-Q vs. Dyna-Q+ : Blocking Maze, Shortcut Maze
import numpy as np
import matplotlib.pyplot as plt
from abc import *
width = 9
height = 6
actions = ["up", "down", "left", "right"]
class Env(metaclass=ABCMeta):
def __init__(self, obstacles, start_pos, end_pos, change_step, last_step):
self.obstacles = list(obstacles)
self.start_pos = start_pos
self.end_pos = end_pos
self.change_step = change_step
self.last_step = last_step
self.state = None
self.step = None
def _getStateIdx(self):
return self.state[0] * width + self.state[1]
def _isBorder(self, pos):
if pos[0] < 0 or pos[0] >= height or pos[1] < 0 or pos[1] >= width:
return True
else:
return False
def _isObstacle(self, pos):
if tuple(pos) in self.obstacles:
return True
else:
return False
def init(self):
self.state = list(self.start_pos)
self.step = 0
return self.step, self._getStateIdx()
def interact(self, action):
self.step += 1
if self.step == self.change_step: # env changes
self.change_func()
if action == 0: # up
new_state = [self.state[0] - 1, self.state[1]]
elif action == 1: # down
new_state = [self.state[0] + 1, self.state[1]]
elif action == 2: # left
new_state = [self.state[0], self.state[1] - 1]
elif action == 3: # right
new_state = [self.state[0], self.state[1] + 1]
else:
raise Exception("Invalid param:action")
if self._isBorder(new_state) or self._isObstacle(new_state):
R = 0
self.state = self.state
elif new_state == list(self.end_pos): # goal
R = 1
self.state = list(self.start_pos)
else:
R = 0
self.state = new_state
return self.step, self._getStateIdx(), R
@abstractmethod
def change_func(self):
pass
class Env_BlockingMaze(Env):
def __init__(self):
super().__init__(obstacles=((3, 0), (3, 1), (3, 2), (3, 3), (3, 4), (3, 5), (3, 6), (3, 7)), start_pos=(5, 3), end_pos=(0, 8), change_step=1000, last_step=3000)
self.name = "Blocking Maze"
def change_func(self):
self.obstacles.remove((3, 0))
self.obstacles.append((3, 8))
class Env_ShortcutMaze(Env):
def __init__(self):
super().__init__(obstacles=((3, 1), (3, 2), (3, 3), (3, 4), (3, 5), (3, 6), (3, 7), (3, 8)), start_pos=(5, 3), end_pos=(0, 8), change_step=3000, last_step=6000)
self.name = "Shortcut Maze"
def change_func(self):
self.obstacles.remove((3, 8))
class DynaQ:
class Model:
def __init__(self):
self.model = dict()
def add(self, state, action, reward, next_state):
if state not in self.model.keys():
self.model[state] = dict()
self.model[state][action] = [reward, next_state]
def getRandomSARS(self):
state = np.random.choice(list(self.model.keys()))
action = np.random.choice(list(self.model[state].keys()))
reward, next_state = self.model[state][action]
return state, action, reward, next_state
def __init__(self, env, planning_num=10, alpha=1.0, gamma=0.9, epsilon=0.1):
self.env = env
self.planning_num = planning_num
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.Q = np.zeros((width * height, len(actions)))
self.model = self.Model()
def policy(self, state):
if np.random.random() < self.epsilon: # exploration
return np.random.choice(len(actions))
else: # exploitation
max_actions = np.argwhere(self.Q[state] == np.max(self.Q[state])).flatten()
return np.random.choice(max_actions)
def learn(self):
env = self.env()
rewards = np.zeros(env.last_step + 1)
step, S = env.init()
while True:
A = self.policy(state=S)
step, S_, R = env.interact(A)
self.Q[S, A] = self.Q[S, A] + self.alpha * (R + self.gamma * np.max(self.Q[S_]) - self.Q[S, A])
self.model.add(state=S, action=A, reward=R, next_state=S_)
S = S_
rewards[step] = R
for n in range(self.planning_num):
pS, pA, pR, pS_ = self.model.getRandomSARS()
self.Q[pS, pA] = self.Q[pS, pA] + self.alpha * (pR + self.gamma * np.max(self.Q[pS_]) - self.Q[pS, pA])
if step == env.last_step:
break
return rewards
class DynaQplus:
class Model:
def __init__(self, kappa):
self.kappa = kappa
self.model = dict()
def add(self, state, action, reward, next_state, cur_step):
if state not in self.model.keys():
self.model[state] = dict()
for a in range(len(actions)):
self.model[state][a] = [0, state, 1]
self.model[state][action] = [reward, next_state, cur_step]
def getRandomSARS(self, cur_step):
state = np.random.choice(list(self.model.keys()))
action = np.random.choice(list(self.model[state].keys()))
reward, next_state, last_step = self.model[state][action]
reward = reward + self.kappa * np.sqrt(cur_step - last_step)
return state, action, reward, next_state
def __init__(self, env, planning_num=10, alpha=1.0, gamma=0.9, epsilon=0.1, kappa=1e-3):
self.env = env
self.planning_num = planning_num
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.Q = np.zeros((width * height, len(actions)))
self.model = self.Model(kappa=kappa)
def policy(self, state):
if np.random.random() < self.epsilon: # exploration
return np.random.choice(len(actions))
else: # exploitation
max_actions = np.argwhere(self.Q[state] == np.max(self.Q[state])).flatten()
return np.random.choice(max_actions)
def learn(self):
env = self.env()
rewards = np.zeros(env.last_step + 1)
step, S = env.init()
while True:
A = self.policy(state=S)
step, S_, R = env.interact(A)
self.Q[S, A] = self.Q[S, A] + self.alpha * (R + self.gamma * np.max(self.Q[S_]) - self.Q[S, A])
self.model.add(state=S, action=A, reward=R, next_state=S_, cur_step=step)
S = S_
rewards[step] = R
for n in range(self.planning_num):
pS, pA, pR, pS_ = self.model.getRandomSARS(cur_step=step)
self.Q[pS, pA] = self.Q[pS, pA] + self.alpha * (pR + self.gamma * np.max(self.Q[pS_]) - self.Q[pS, pA])
if step == env.last_step:
break
return rewards
def drawGraph(dyna_q_rewards, dyna_q_plus_rewards, env):
plt.plot(np.arange(len(dyna_q_rewards)), dyna_q_rewards, label="Dyna-Q")
plt.plot(np.arange(len(dyna_q_plus_rewards)), dyna_q_plus_rewards, label="Dyna-Q+")
plt.axvline(x=env().change_step, c='k', linestyle="--", linewidth=0.5)
plt.title(f"{env().name}")
plt.xlabel("Steps")
plt.ylabel("Cumulative Rewards")
plt.legend()
plt.show()
if __name__ == "__main__":
repeats = 30
# Blocking Maze
env = Env_BlockingMaze
dyna_q_rewards = np.zeros(env().last_step + 1)
for repeat in range(repeats):
agent = DynaQ(env=env)
dyna_q_rewards += np.cumsum(agent.learn())
dyna_q_rewards /= repeats
dyna_q_plus_rewards = np.zeros(env().last_step + 1)
for repeat in range(repeats):
agent = DynaQplus(env=env)
dyna_q_plus_rewards += np.cumsum(agent.learn())
dyna_q_plus_rewards /= repeats
drawGraph(dyna_q_rewards, dyna_q_plus_rewards, env)
# Shortcut Maze
env = Env_ShortcutMaze
dyna_q_rewards = np.zeros(env().last_step + 1)
for repeat in range(repeats):
agent = DynaQ(env=env)
dyna_q_rewards += np.cumsum(agent.learn())
dyna_q_rewards /= repeats
dyna_q_plus_rewards = np.zeros(env().last_step + 1)
for repeat in range(repeats):
agent = DynaQplus(env=env)
dyna_q_plus_rewards += np.cumsum(agent.learn())
dyna_q_plus_rewards /= repeats
drawGraph(dyna_q_rewards, dyna_q_plus_rewards, env)코드 설명
- line 9 ~ 71 :
Env클래스- 위 Maze 예제의
Env클래스와 유사. 다만 Maze 예제의Env는 Episodic Task를 위한 환경이었다면, 이Env는 Continuing Task를 위한 환경이다. - line 35 ~ 38 :
Env.init()메소드- 에피소드를 시작하는 메소드
- 현재 시간(time step), 상태 반환
- line 40 ~ 67 :
Env.interact()메소드- 에이전트가 환경과 상호작용하는 메소드
Env.change_step이 되면Env.change_func()메소드가 실행되며 환경이 변함- 현재 시간(time step), 상태, 보상 반환
- 위 Maze 예제의
- line 73 ~ 80 :
Env_BlockingMaze클래스- Blocking Maze 환경을 나타내는 클래스
- line 82 ~ 88 :
Env_ShortcutMaze클래스- Shortcut Maze 환경을 나타내는 클래스
- line 90 ~ 145 :
DynaQ클래스- 위 Maze 예제의
DynaQ클래스와 유사 - line 123 ~ 145 :
DynaQ.learn()메소드- Dyna-Q 방법대로 학습을 진행하는 메소드
- 각 시간마다 받은 보상들의 배열을 반환
- 위 Maze 예제의
- line 147 ~ 208 :
DynaQplus클래스- line 148 ~ 166 :
DynaQplus.Model클래스- line 153 ~ 159 :
DynaQplus.Model.add()메소드- 실제 경험(real experience)을 모델에 추가하는 메소드
- line 156 ~ 157 : 만약 모델에 처음 저장되는
state가 입력되면, 가능한 모든 행동들에 대해 보상 0, 다음 상태state, 시간 1의 정보를 입력한다.
- line 161 ~ 166 :
DynaQplus.Model.getRandomSARS()메소드- 기존에 경험했던 상태-행동 쌍 중 무작위로 하나를 골라 가짜 경험(simulated experience)을 생성
- 보상으로
를 사용 - 상태, 행동, 보상, 다음 상태를 반환
- line 153 ~ 159 :
- line 148 ~ 166 :
- line 210 ~ 219 :
drawGraph()함수- 각 시간별 받은 보상의 누적합을 그리는 함수
- line 221 ~ 256 : main
- line 222 : 반복 횟수 설정
- line 224 ~ 239 : Fig.07 출력
- Dyna-Q 에이전트와 Dyna-Q+ 에이전트의 학습을 각각
repeat번 반복한 후 그 결과를 평균내어 그래프를 그림
- Dyna-Q 에이전트와 Dyna-Q+ 에이전트의 학습을 각각
- line 241 ~ 256 : Fig.08 출력
- Dyna-Q 에이전트와 Dyna-Q+ 에이전트의 학습을 각각
repeat번 반복한 후 그 결과를 평균내어 그래프를 그림
- Dyna-Q 에이전트와 Dyna-Q+ 에이전트의 학습을 각각
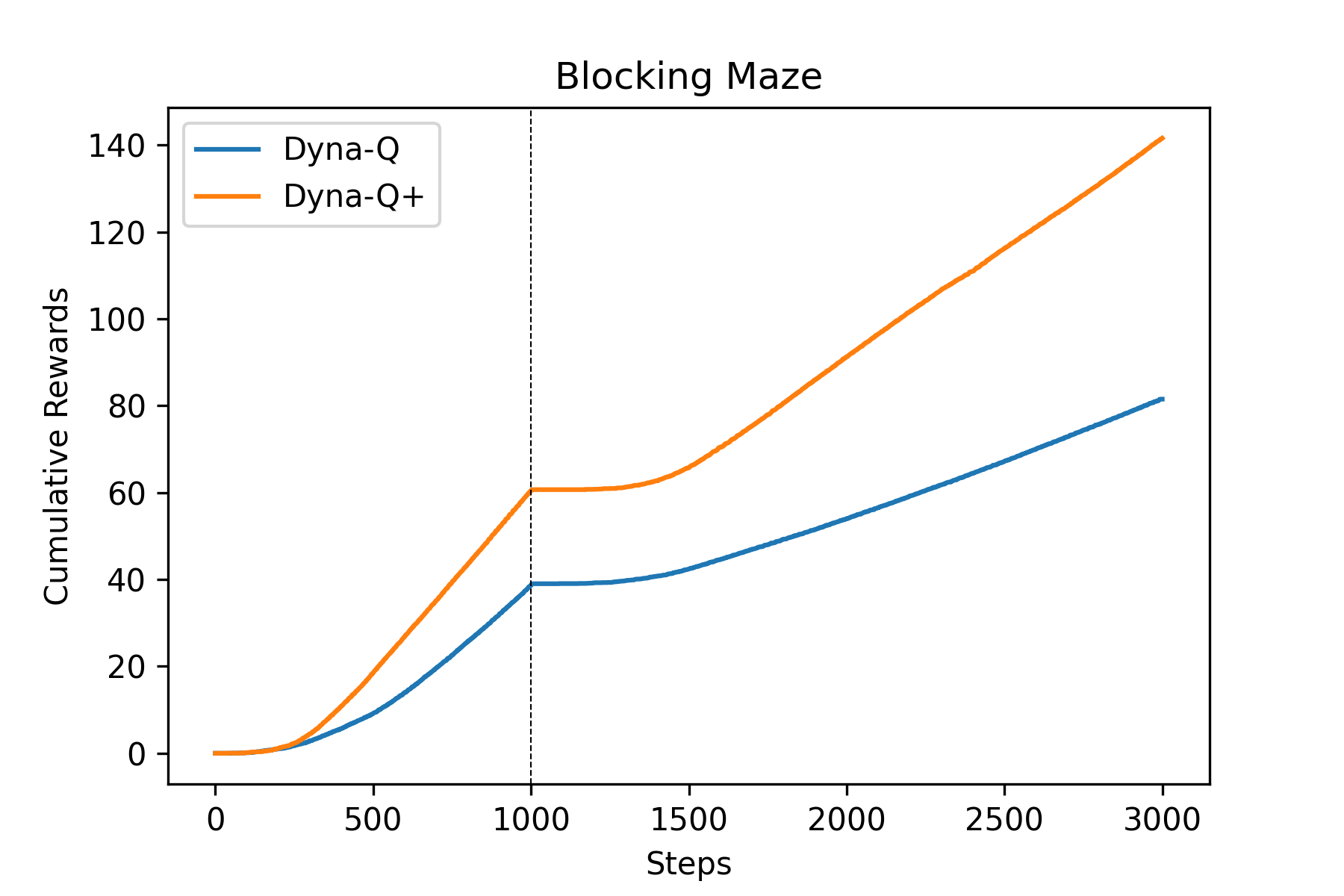
Fig.07 Dyna-Q vs. Dyna-Q+ : Blocking Maze
파란색 선은 Dyna-Q 에이전트, 주황색 선은 Dyna-Q+ 에이전트의 결과를 나타낸다. 점선은 환경이 변한 시간을 나타낸다.
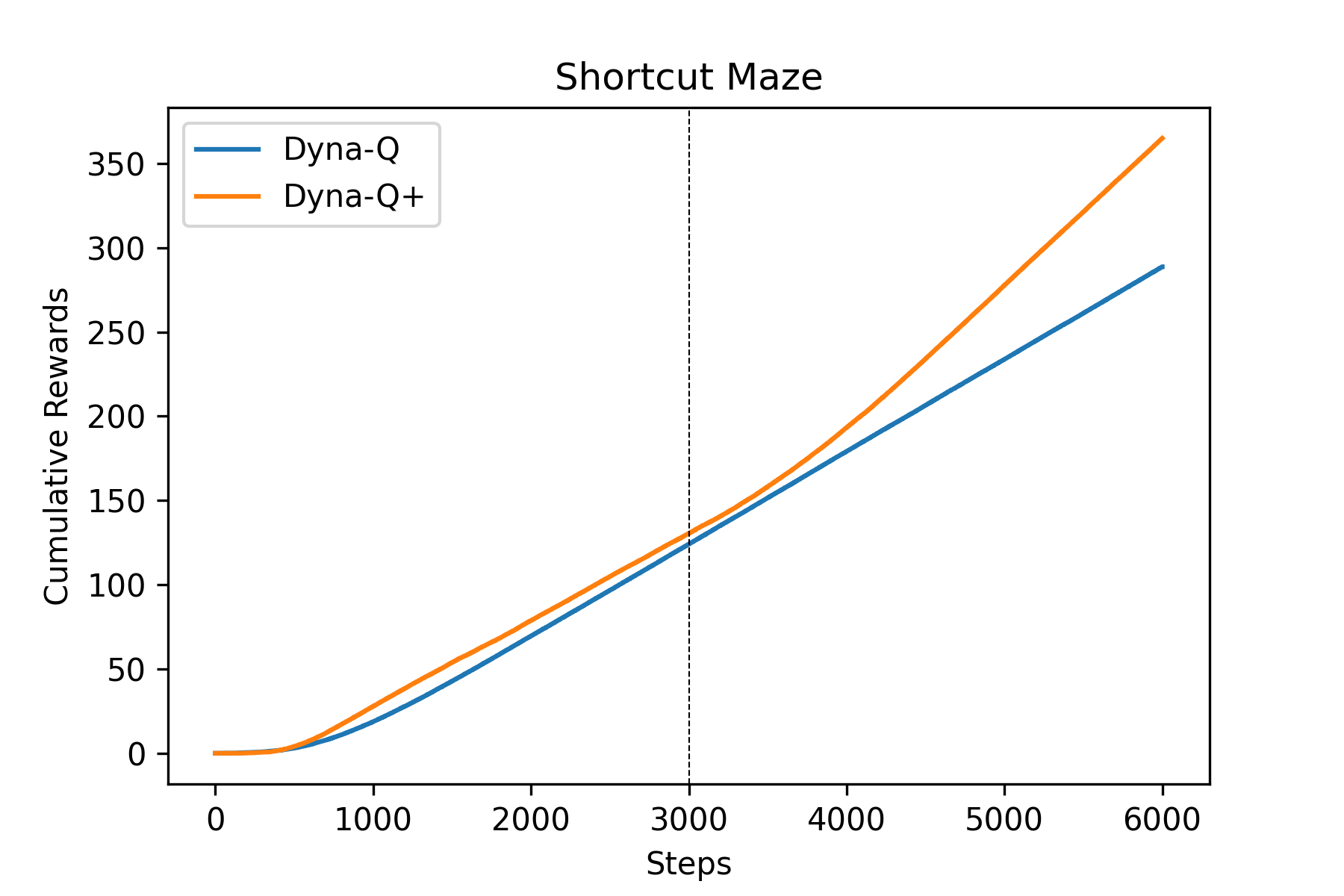
Fig.08 Dyna-Q vs. Dyna-Q+ : Shortcut Maze
파란색 선은 Dyna-Q 에이전트, 주황색 선은 Dyna-Q+ 에이전트의 결과를 나타낸다. 점선은 환경이 변한 시간을 나타낸다.
Fig.07을 보면 환경이 바뀐 후 Dyna-Q+ 에이전트(주황색)가 Dyna-Q 에이전트(파란색)보다 좀 더 일찍 수평 구간(= 보상을 받지 못하는 상태)를 벗어난다. 즉 Dyna-Q+가 Dyna-Q에 비해 환경의 변화에 좀 더 잘 대응했다는 것이다. 마찬가지로, Fig.08을 보면 환경이 바뀐 이후에도 Dyna-Q 에이전트는 환경의 변화를 인지하지 못하고 계속 같은 기울기를 유지하지만, Dyna-Q+ 에이전트는 환경의 변화를 감지해 기울기가 조금 더 커진 것을(= 지름길을 찾았다는 것을) 볼 수 있다.
Fig.07, Fig.08을 보면 환경이 바뀌기 전에도 Dyna-Q+ 에이전트가 Dyna-Q 에이전트에 비해 성능이 좋은 것을 볼 수 있다. 이는 Dyna-Q+와 Dyna-Q의 성능 차이가 아니라, Blocking Maze와 Shortcut Maze의 특성 때문에 그렇다. Blocking Maze와 Shortcut Maze에서 목적지(G)에 도달하려면 일단 오른쪽 혹은 왼쪽의 좁은 길을 찾아야 한다. Dyna-Q+는 Dyna-Q에 비해 훨씬 더 탐색적(exploratory)이므로 Dyna-Q+ 에이전트가 Dyna-Q 에이전트보다 오른쪽 혹은 왼쪽의 좁은 길을 훨씬 더 잘 찾는다. 만약 하이퍼파라미터 값을 조금 다르게 쓰면[10] 다음과 같이 Dyna-Q+의 초기 성능이 Dyna-Q보다 안 좋게 나올 수도 있다.[11]
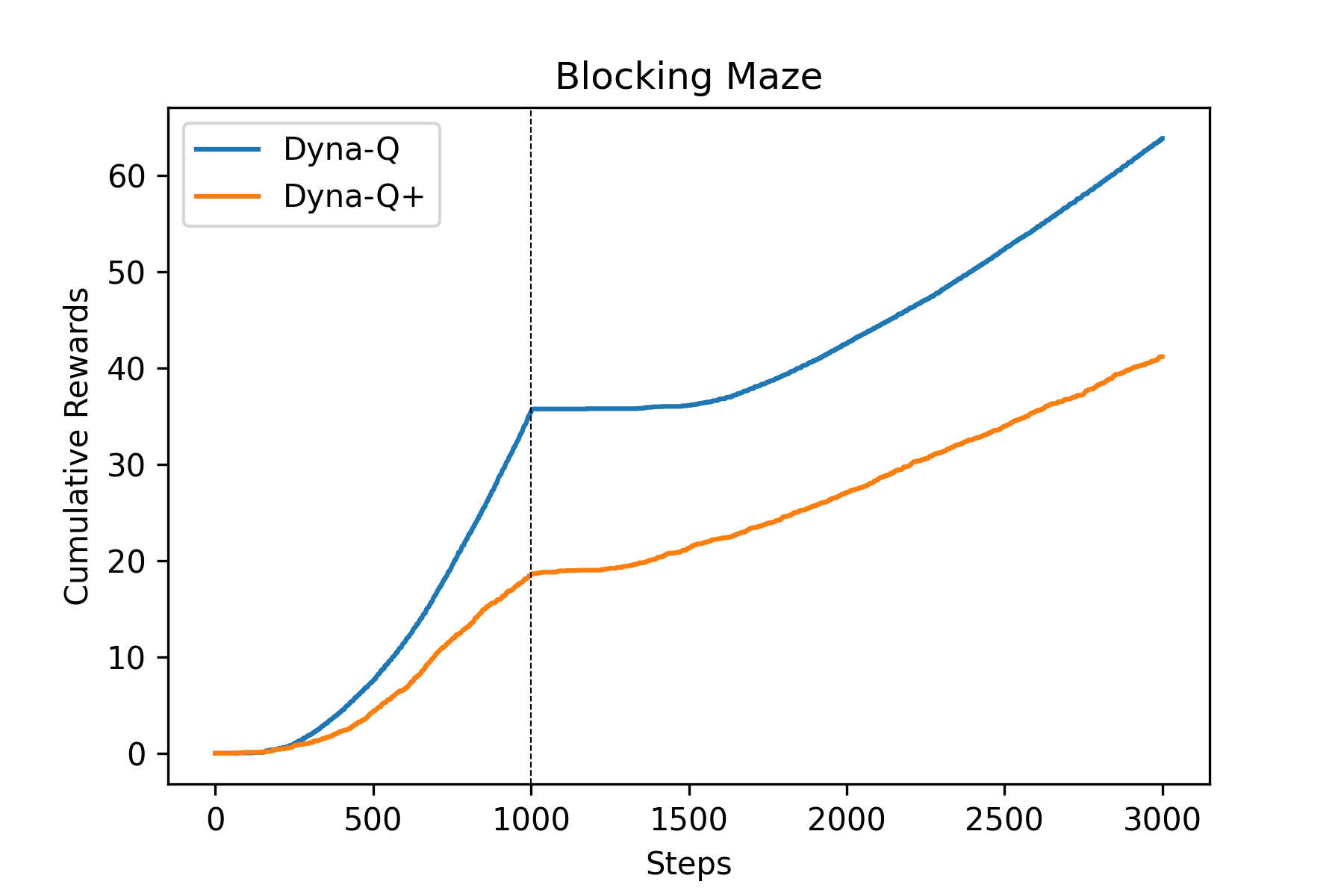
Fig.09 Dyna-Q vs. Dyna-Q+ : Blocking Maze 2
Prioritized Sweeping
Dyna-Q에서의 Planning 과정을 한번 생각해 보자. Dyna-Q의 Planning은 에이전트가 경험했던 상태-행동 쌍 중 무작위로 하나를 선택(uniform selection)해 해당 가치를 업데이트하는 식으로 이루어졌다. 그러나 과연 이 방법이 효율적인 방법일까?
예를 들어, 위 Maze 문제에서 Dyna-Q 에이전트가 처음으로 G에 도달해 보상 1을 막 받은 시점을 생각해 보자. 에이전트는 이 실제 경험을 이용해 G에 도달하기 바로 직전 상태-행동 쌍의 가치를 업데이트한다. 그리고 Planning을 시작한다. 그러나 현재 에이전트의 행동-가치 함수 G에 도달하기 바로 직전 상태-행동 쌍에서를 제외하곤 모두 초기값 0에서 아무런 업데이트가 없었다. 하지만 Dyna-Q Planning에선 무작위 선택을 하므로, 이전 과정에서 가치가 업데이트되지 않은 상태-행동 쌍이 선택되어 가치 함수가 전혀 업데이트되지 않는, 의미없는 Planning이 일어날 수 있다. 만약 풀고자 하는 문제의 상태-행동 쌍 공간이 넓다면 이는 학습 속도를 엄청나게 저해시키는 문제가 된다.
그렇다면 어떻게 하면 효율적인 Planning이 가능할까? 가치 업데이트가 될 가능성이 있는 '유용한' 상태-행동 쌍에서부터 거꾸로 가면서 Planning을 진행하면 효율적인 Planning이 가능하다. 구체적으로, Planning을 진행할 상태-행동 쌍을 무작위로 고르는 것이 아니라, 이전 단계에서 가치가 업데이트된 상태-행동 쌍에서부터 거꾸로 가면서(backward focusing) Planning을 진행하는 것이다.
그렇다면 만약 이전 과정에서 여러 상태-행동 쌍의 가치들이 업데이트되어 '유용한' 상태-행동 쌍이 여러 개이면 어떻게 해야 할까? 이 경우엔 가치 변동량이 더 큰 상태-행동 쌍부터 먼저 Planning을 진행하는 것이 효율적이다. 가치 변동량이 더 클수록 더 극적이고 중요한 업데이트였을 것이고, 더 시급히 전파하는 것이 옳기 때문이다.
이 두 가지 아이디어를 Prioritized Sweeping이라 한다. 구체적으로, 우선순위 큐(priority queue)를 하나 두고, 가치 변동량이 특정 임계값
Pseudo Code : Dyna-Q with Prioritized Sweeping on Deterministic Environment
모든
모든
Loop forever:
If
Loop repeat
If
break
Loop for
If
확률론적인 환경(stochastic environment)으로의 확장도 간단하다. 각 상태-행동 쌍이 시행되었을 때 어떤 상태로 몇 번 전이했는지를 모델이 기억하게 한 후, Planning 때 이 값을 이용하여 확률을 계산해 (이때까지 했던 Sample Update가 아닌) Expected Update를 진행하면 된다.
예제 : Prioritized Sweeping on Mazes
위 Maze 문제를 약간 변형한 다음 예제를 살펴보자.
Scaling Maze
Fig.02의 미로의 해상도(resolution)를 변경하여 Fig.10과 같은 미로들을 얻었다. 각 미로들에서의 규칙은 Maze 문제에서와 동일하다.
- 미로의 크기는 세로 (6 ×
scale), 가로 (9 ×scale)이다. - 에피소드는 S(2 ×
scale, 0 ×scale)에서 시작한다. - 각 칸에서 에이전트는 상, 하, 좌, 우, 4방향으로 한 칸씩 움직일 수 있다. 단, 장애물(검은 칸) 또는 미로 바깥으로는 이동할 수 없다.
- G(0 ×
scale, 8 ×scale)로의 이동은 +1의 보상을 받는다. 이를 제외한 모든 이동은 0의 보상을 받는다. - 에이전트가 G에 도달하면 곧바로 S로 이동해 새로운 에피소드를 시작한다.

Fig.10 Scaling Maze
Fig.02의 미로의 해상도를 변경하여 위와 같은 미로들을 얻었다.
이들 미로들에 대해 순수 Dyna-Q만을 사용할 때와 Prioritized Sweeping이 적용된 Dyna-Q를 사용할 때의 행동 가치 함수 업데이트 횟수의 차이를 비교해 보자.
Code : Scaling Maze
import numpy as np
from queue import PriorityQueue
import matplotlib.pyplot as plt
class Env:
def __init__(self, scale):
self.height = 6 * scale
self.width = 9 * scale
self.obstacles = self._getObstacles(scale)
self.start_pos = (2 * scale, 0 * scale)
self.end_pos = (0 * scale, 8 * scale)
self.state = None
self.step = None
def _getStateIdx(self):
return self.state[0] * self.width + self.state[1]
def _isBorder(self, pos):
if pos[0] < 0 or pos[0] >= self.height or pos[1] < 0 or pos[1] >= self.width:
return True
else:
return False
def _isObstacle(self, pos):
if tuple(pos) in self.obstacles:
return True
else:
return False
def _getObstacles(self, scale):
obstacles = []
for i in range(1, 4):
for j in range(2, 3):
obstacles.append((i * scale, j * scale))
for i in range(4, 5):
for j in range(5, 6):
obstacles.append((i * scale, j * scale))
for i in range(0, 3):
for j in range(7, 8):
obstacles.append((i * scale, j * scale))
return obstacles
def init(self):
self.state = list(self.start_pos)
self.step = 0
return self.step, self._getStateIdx(), 0
def interact(self, action):
self.step += 1
if action == 0: # up
new_state = [self.state[0] - 1, self.state[1]]
elif action == 1: # down
new_state = [self.state[0] + 1, self.state[1]]
elif action == 2: # left
new_state = [self.state[0], self.state[1] - 1]
elif action == 3: # right
new_state = [self.state[0], self.state[1] + 1]
else:
raise Exception("Invalid param:action")
if self._isBorder(new_state) or self._isObstacle(new_state):
R = 0
self.state = self.state
elif new_state == list(self.end_pos): # goal
R = 1
self.state = list(self.start_pos)
else:
R = 0
self.state = new_state
return self.step, self._getStateIdx(), R
class DynaQ:
class Model:
def __init__(self):
self.model = dict()
self.predecessors = dict()
def add(self, state, action, reward, next_state):
if not state in self.model.keys():
self.model[state] = dict()
self.model[state][action] = [reward, next_state]
if not next_state in self.predecessors.keys():
self.predecessors[next_state] = set()
self.predecessors[next_state].add((state, action, reward))
def getRandomSA(self):
state = np.random.choice(list(self.model.keys()))
action = np.random.choice(list(self.model[state].keys()))
return state, action
def getRS_(self, state, action):
reward, next_state = self.model[state][action]
return reward, next_state
def getPredecessors(self, state):
return self.predecessors[state]
def __init__(self, scale, planning_num=5, alpha=0.5, gamma=0.95, epsilon=0.1):
self.scale = scale
self.planning_num = planning_num
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.env = Env(scale=scale)
self.updates = 0
self.Q = np.zeros((self.env.width * self.env.height, 4))
self.model = self.Model()
def policy(self, state, greedy=False):
if greedy: # greedy
max_actions = np.argwhere(self.Q[state] == np.max(self.Q[state])).flatten()
return np.random.choice(max_actions)
else: # ε-greedy
if np.random.random() < self.epsilon: # exploration
return np.random.choice(4)
else: # exploitation
max_actions = np.argwhere(self.Q[state] == np.max(self.Q[state])).flatten()
return np.random.choice(max_actions)
def isOptimal(self):
tolerance_rate = 1.2
env = Env(scale=self.scale)
step, S, R = env.init()
while True:
if R == 1:
break
if step > 14 * self.scale * tolerance_rate:
return False
A = self.policy(state=S, greedy=True)
step, S_, R = env.interact(A)
S = S_
return True
def learn(self):
step, S, R = self.env.init()
while True:
A = self.policy(state=S)
step, S_, R = self.env.interact(A)
self.Q[S, A] = self.Q[S, A] + self.alpha * (R + self.gamma * np.max(self.Q[S_]) - self.Q[S, A])
self.updates += 1
if self.isOptimal():
break
self.model.add(state=S, action=A, reward=R, next_state=S_)
S = S_
break_while = False
for n in range(self.planning_num):
pS, pA = self.model.getRandomSA()
pR, pS_ = self.model.getRS_(pS, pA)
self.Q[pS, pA] = self.Q[pS, pA] + self.alpha * (pR + self.gamma * np.max(self.Q[pS_]) - self.Q[pS, pA])
self.updates += 1
if self.isOptimal():
break_while = True
break
if break_while:
break
return self.updates
class DynaQ_PrioritizedSweeping(DynaQ):
def __init__(self, scale, planning_num=5, alpha=0.5, gamma=0.95, epsilon=0.1, omega=0.0001):
super().__init__(scale=scale, planning_num=planning_num, alpha=alpha, gamma=gamma, epsilon=epsilon)
self.omega = omega
self.pqueue = PriorityQueue()
def putInPQueue(self, S, A, R, S_):
P = abs(R + self.gamma * np.max(self.Q[S_]) - self.Q[S, A])
if P > self.omega:
self.pqueue.put((-P, (S, A)))
def learn(self):
step, S, R = self.env.init()
while True:
A = self.policy(state=S)
step, S_, R = self.env.interact(A)
self.model.add(state=S, action=A, reward=R, next_state=S_)
self.putInPQueue(S, A, R, S_)
S = S_
break_while = False
for n in range(self.planning_num + 1):
if self.pqueue.empty():
break
pS, pA = self.pqueue.get()[1]
pR, pS_ = self.model.getRS_(pS, pA)
self.Q[pS, pA] = self.Q[pS, pA] + self.alpha * (pR + self.gamma * np.max(self.Q[pS_]) - self.Q[pS, pA])
self.updates += 1
if self.isOptimal():
break_while = True
break
for (S_bar, A_bar, R_bar) in self.model.getPredecessors(pS):
self.putInPQueue(S_bar, A_bar, R_bar, pS)
if break_while:
break
return self.updates
def drawGraph(scales, results):
for i, name in enumerate(["Dyna-Q", "Dyna-Q-PS"]):
plt.plot(scales, results[:, i], label=name)
plt.title("Dyna-Q vs. Dyna-Q-PS")
plt.xlabel("Scale (# of states)")
plt.ylabel("Updates until Optimal Solution")
plt.xticks(scales)
plt.yscale("log")
plt.legend()
plt.show()
if __name__ == "__main__":
repeats = 10
scales = [x for x in range(1, 11)]
results = np.zeros((len(scales), 2))
for i, scale in enumerate(scales):
dyna_q_results = []
for repeat in range(repeats):
agent = DynaQ(scale=scale)
dyna_q_results.append(agent.learn())
dyna_q_ps_results = []
for repeat in range(repeats):
agent = DynaQ_PrioritizedSweeping(scale=scale)
dyna_q_ps_results.append(agent.learn())
results[i] = (sum(dyna_q_results) / repeats, sum(dyna_q_ps_results) / repeats)
drawGraph(scales=scales, results=results)코드 설명
- line 5 ~ 75 :
Env클래스- 위 Maze 예제의
Env클래스와 유사. 다만 이Env는scale값에 따라 스케일러블(scalable)하다. - line 30 ~ 44 :
Env._getObstacles()메소드scale값에 따라 장애물의 좌표를 스케일해 반환하는 메소드
- line 46 ~ 49 :
Env.init()메소드- 에피소드를 시작하는 메소드
- 현재 시간(time step), 상태, 보상(0) 반환
- 위 Maze 예제의
- line 77 ~ 177 :
DynaQ클래스- 위 Maze 예제의
DynaQ클래스와 유사 - line 78 ~ 102 :
DynaQ.Model클래스- line 79 ~ 81 :
DynaQ.Model.__init__()메소드- Dyna-Q 모델의 초기화를 진행하는 메소드
preprocessors: 상태를 키로, 해당 상태로 바로 전이하는 이전 상태-행동 쌍과 그때의 보상을 값으로 저장하고 있는 딕셔너리
- line 101 ~ 102 :
DynaQ.Model.getPredecessors()메소드state로 전이하는 모든 (상태, 행동, 보상) 쌍을 반환하는 메소드
- line 79 ~ 81 :
- line 128 ~ 144 :
DynaQ.isOptimal()메소드- 현재 학습된
Q가 최적의 가치 함수인지를 확인 - S에서 몇 단계 안에 G에 도달하는지를 테스트한다.
scale = 1일 때 S에서 G까지의 최단 거리는 14이므로, 테스트 결과14 * scale * tolerance_rate이상 걸리는Q는 최적 가치 함수가 아닌 것으로, 그 안에 G에 도달하는Q는 최적 가치 함수인 것으로 판단.tolerance_rate는 테스트 속도 향상을 위해 테스트 기준을 조금 느슨하게 만들어주는 값으로, 위 코드에서는 1.2를 사용
- 현재 학습된
- line 146 ~ 177 :
DynaQ.learn()메소드- 실제 학습을 진행하는 메소드
- line 152 ~ 156, line 167 ~ 171 :
Q업데이트 후DynaQ.isOptimal()메소드를 이용해 최적 가치 함수가 되었는지 매번 확인- 만약 최적 가치 함수가 되었으면 이때까지
Q가 몇 번 업데이트되었는지updates값을 반환
- 만약 최적 가치 함수가 되었으면 이때까지
- 위 Maze 예제의
- line 179 ~ 222 :
DynaQ_PrioritizedSweeping클래스- line 185 ~ 188 :
DynaQ_PrioritizedSweeping.putInPQueue()메소드- 입력된 경험으로 인해
Q가 업데이트되는 양을 계산해여(P), 이 값이omega보다 크면 우선순위 큐(pqueue)에 추가하는 메소드
- 입력된 경험으로 인해
- line 190 ~ 222 :
DynaQ_PrioritizedSweeping.learn()메소드- 실제 학습을 진행하는 메소드
- line 197 : 실제 경험을 할 때마다
DynaQ_PrioritizedSweeping.putInPQueue()메소드를 이용해 이 정보를 우선순위 큐에 넣는다. - line 209 ~ 214 :
Q업데이트 후DynaQ.isOptimal()메소드를 이용해 최적 가치 함수가 되었는지 매번 확인 - line 216 ~ 217 :
Q업데이트 후 업데이트된 상태로 전이하는 직전 상태-행동 쌍들을DynaQ_PrioritizedSweeping.putInPQueue()메소드를 이용해 우선순위 큐에 넣는다.
- line 185 ~ 188 :
- line 224 ~ 234 :
drawGraph()함수- Fig.11을 그리는 함수
- line 236 ~ 255 : main
- line 237 : 반복 횟수
repeats설정 - line 239 : 사용할
scale값 설정 (1, 2, ..., 10) - line 242 ~ 255 : 각
scale값에 대해 최적 가치 함수가 되기까지 몇 번의 업데이트가 있었는지repeats번 시험한 후 그 결과를 평균내어 Fig.11을 그린다.
- line 237 : 반복 횟수
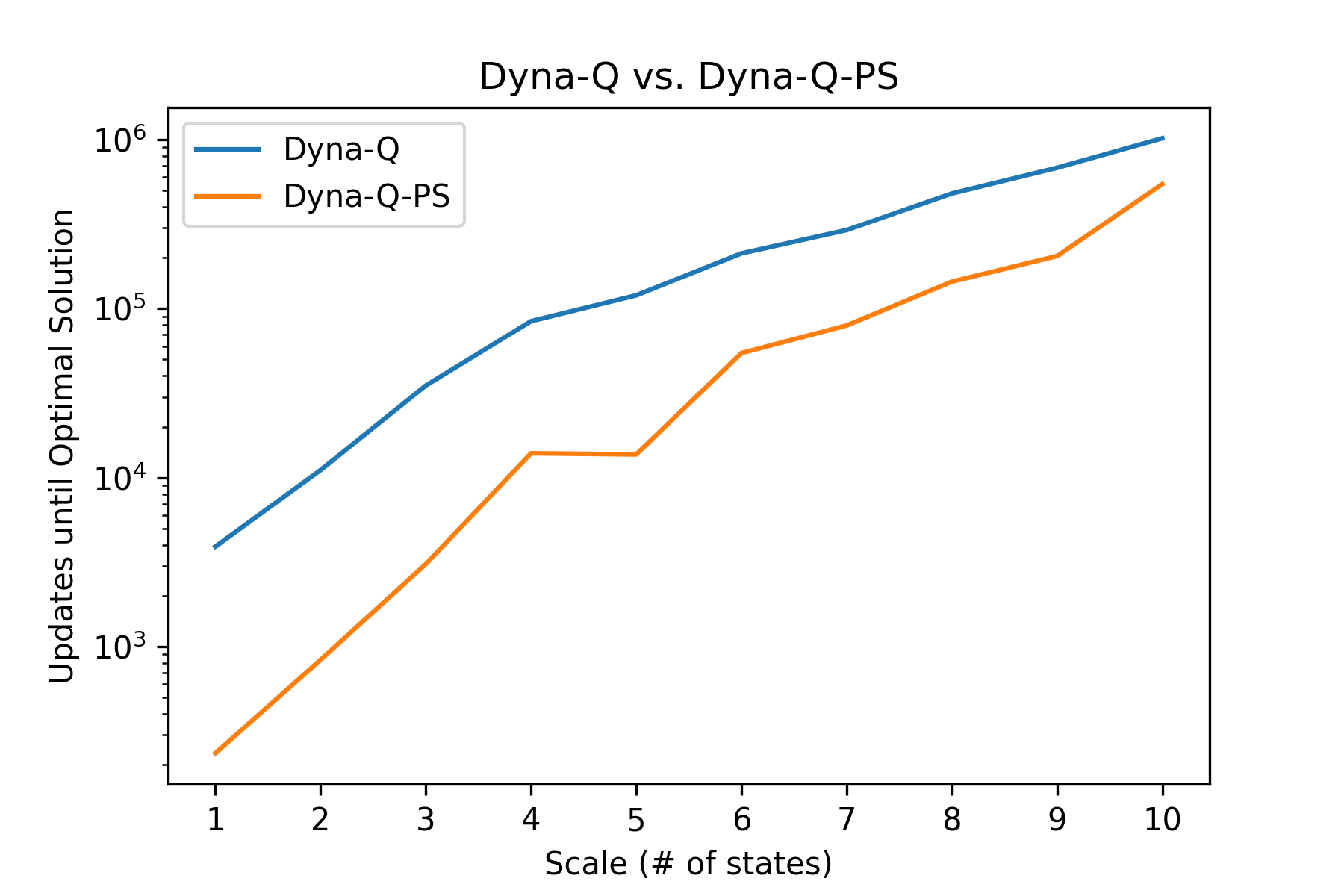
Fig.11 Dyna-Q vs. Dyna-Q with Prioritized Sweeping
파란색 선은 Dyna-Q 에이전트, 주황색 선은 Prioritized Sweeping을 사용하는 Dyna-Q 에이전트의 결과를 나타낸다.
위 결과에서 볼 수 있듯이 Prioritized Sweeping을 사용하는 Dyna-Q 에이전트는 순수한 Dyna-Q 에이전트를 사용할 때보다 언제나 빠르게 최적 가치 함수로 수렴한다.
여담
Prioritized Sweeping은 Planning 효율을 높이는 한 가지 방법일 뿐, 최고의 방법은 아니다. Prioritized Sweeping은 많은 한계를 가지고 있다. 대표적으로 확률론적 환경에서 Prioritized Sweeping은 Expected Update를 사용하는데, 이 과정에서 확률이 낮은 전이(low-probability transition)까지 모두 계산하므로 계산 효율이 낮다는 한계점이 있다.[12]
주사위의 각 눈이 나올 확률은 모두 1/6로 동일하므로 1, 2, 3, 4, 5, 6 중 한 숫자가 완전 무작위로(uniformly) 출력될 것이다. ↩︎
엄밀히 말하면, 이 설명은 State-space Planning에 대한 설명이다. Planning은 State-space Planning과 Plan-space Planning, 이렇게 두 가지로 크게 구분할 수 있다. Plan-space Planning은 Plan 공간(Plan space)을 (일반적으로 진화적 방법(evolutionary method)을 사용해) 탐색하며 최적의 Plan을 찾는 방법이다(최적의 Plan으로 만들어지는 정책이 최적 정책이 된다). Plan-space Planning은 State-space Planning에 비해 조금 더 유연하다는 장점이 있으나, (RL에서 특히 중점적으로 다루는) 연속적 확률 결정 문제(stochastic sequential decision problem)에는 효율적으로 적용하기 어렵다는 단점이 있다. 따라서 일반적으로 RL에서는 State-space Planning을 사용한다. ↩︎
모델을 사용하여, 모델이 만들어낸 가짜 경험(simulated experience)을 이용해 에이전트를 학습시키는 것을 Planning이라 한다. 한편 앞에서 배웠던 것처럼, 모델을 사용하지 않고 실제 경험(real experience)을 이용해 에이전트를 학습시키는 것을 Learning이라 한다(비록 한국어로는 둘 다 학습이라 하지만 말이다). 그래서 Model-free Method 버전의 MC Method, TD Method는 각각 MC Learning, TD Learning이라, Model-based Method 버전의 MC Method, TD Method는 MC Planning, TD Planning이라 부른다. ↩︎
이를 모델 학습(Model Learning) 이라 한다. ↩︎
참고로 가짜 경험(simulated experience) 생성을 위해, 시작 상태(starting state)와 행동(action)을 선택해 모델에 입력하는 과정을 Search Control이라 한다. ↩︎
일반적으로 Dyna 알고리즘에서는 (Dyna-Q에서처럼) Direct RL과 Indirect RL에서 동일한 RL Method를 사용한다. ↩︎
아래 코드에서 Acting, Learning, Planning은 순차적으로(sequentially) 실행되는 것처럼 서술되어 있다. 하지만 이는 설명의 명확성을 위한 것으로, 원래 Dyna 알고리즘에서 Acting, Learning, Planning은 동시에 시행된다. 즉, 환경과 상호작용을 하는 동시에 기존 경험들을 토대로 Learning(Direct RL)을 진행하고, 또 동시에 모델 학습 및 Planning(Indirect RL)을 진행한다. 사실 Planning을 통해 더 좋은 정책(policy)을 빠르게 학습하면 학습할수록 실제 받는 보상의 크기가 커지므로, Planning은 가능한 한 빨리 하는 것이 좋다. ↩︎
에이전트가 잘 학습되었다는 것은 적은 수의 step을 써서(= 최단경로로) G에 도달했다는 것이다. ↩︎
사실 첫 번째 에피소드에서는 모델이 비어있기 때문에, Planning을 했을 때와 안 했을 때의 차이가 없다. ↩︎
Fig.07, Fig.08을 얻을 때는
, , , , 을 사용했다. Fig.09를 얻을 때는 , , , , 을 사용했다. ↩︎ 이렇게 해도 수평 구간은 Dyna-Q+가 Dyna-Q보다 더 잘 탈출하는 것을 볼 수 있다. ↩︎
단 결정론적 환경에서 Prioritized Sweeping은 Sample Update를 사용하므로 이 한계점은 해당사항이 없다. 심지어 결정론적 환경에서는 더 '유용한' 업데이트부터 먼저 처리하기에 가치 함수의 참값에 빠르게 접근할 수 있다. ↩︎
Comments