이전 글에서 살펴보았던 MC Method를 이용하면 환경에 대한 지식 없이도 경험만으로 최적 가치 함수 및 최적 정책을 찾을 수 있었다. 예를 들어 Nonstationary한 환경에서 every-visit MC Method를 사용하는 상황을 생각해 보자. 시간 에서, 적절한 상수 에 대해 가치 함수 는 실제로 관측된 Sample Return 를 이용해 다음과 같이 업데이트된다.[1]
그런데 MC Method는 한 에피소드가 끝나야 학습을 진행할 수 있다는 단점이 있다. Sample Return 를 계산하려면 한 에피소드가 끝나야 하기 때문이다. 이 때문에 에피소드의 길이가 긴 경우 MC Method를 이용하면 학습 시간이 너무 길어진다. 또한 MC Method는 실시간으로 학습할 수 없고, Continuing Task에서는 사용할 수 없다.
그런데 생각해 보면 학습을 위해 꼭 에피소드의 종료까지 기다릴 필요가 없다. 상태 에서 로 전이하면서 보상 을 받는 것을 관측했다고 해 보자. 그렇다면, 에서의 가치 의 추정값은 관측값 과 또 다른 추정값 을 이용해 다음과 같이 유의미한 업데이트할 수 있다.
이런 식으로 한 추정값()을 관측값()과 다른 추정값()을 이용해 추정하는 방법을 TD(Temporal-Difference) Method라 한다. 관측값을 통해 추정값을 추정한다는 점에서 TD Method는 MC Method와 유사하다. 또한 다른 추정값을 통해 한 추정값을 추정한다는 점에서[2] TD Method는 DP와 유사하다. 즉 TD Method는 DP와 MC Method를 결합한 방법이라 이해할 수 있다.
DP에서는 보상과 다음 상태의 확률 분포 등을 알려주는, 환경에 대한 모델(model)이 필요했다. 그러나 TD Method에서는 모델이 없어도 된다. TD Method는 MC Method에서처럼 경험으로부터 학습이 가능하다. 또한 TD Method에서는[3] 한 스텝(time step)만 기다리면 되기 때문에 MC Method와 다르게 실시간 학습(online learning)이 가능하다.
이 식은 TD(0) Method 또는 one-step TD Method라 불리는, 가장 간단한 TD Method 업데이트 식이다.
(Constant-) MC Method에서는 가 와 가까워지도록 업데이트가 진행된다. 다시 말해, MC Method의 업데이트의 목표(target)는 이다. 한편, TD(0) Method에서는 가 와 가까워지도록 업데이트가 진행된다. 다시 말해, TD(0) Method의 업데이트의 목표는 이다.
TD(0) Method를 일반화하면 TD() Method, -step TD Method라는 TD Method가 된다. 이들에 대해서는 다음 글에서 조금 더 자세히 다루도록 하겠다. 이번 글에서는 TD(0) Method를 이용하여 Prediction 문제와 Control 문제를 풀어보도록 하자.
을 배웠다. DP에서는 위의 (2)번 식을 이용해 최적 정책을 추정했다. DP가 추정인 이유는 계산 과정에서 현재 단계에서 정확히 알 수 없는 대신 추정값인 를 쓰기 때문이다(bootstrapping). 한편 MC Method에서는 위의 (1)번 식을 이용해 최적 정책을 추정했다. MC Method가 추정인 이유는 (환경에 대한 모든 정보를 모르므로) 대신 샘플링된 값(Sample Return)을 사용하기 때문이다.
DP와 MC Method를 결합한 TD Method의 결과 역시 추정값이다. TD Method는 (2)번 식을 이용해 최적 정책을 추정하는데, 현재 단계에서 정확히 알 수 없는 대신 추정값인 를 쓰고, 기댓값 대신 샘플링된 값을 사용하기 때문이다.
참고로 DP처럼 가능한 모든 다음 값들을 이용해 현재 값을 업데이트하는 것을 expected update라 부른다. 반면 MC Method나 TD Method에서처럼 샘플링된 다음 값 하나만을 이용해 현재 값을 얻베이트하는 것을 sample update라 부른다.
를 계산하려면 보상 과 상태 가 필요하기에, 번째 TD error 는 시점 에서야 계산 가능해진다.
비슷하게, (Constant-) MC Method의 업데이트 식
에서 대괄호 안 빨간색 테두리 영역을 MC error라 부른다. 이때 한 에피소드 동안 가 바뀌지 않는다면,[4] MC error는 다음과 같이 TD error의 합 형태로 표현할 수 있다.
TD(0) Method에서는 매 시간 간격마다 가 업데이트되므로 위 성질이 완벽히 성립하진 않는다. 그러나 의 크기가 충분히 작다면 위 성질은 (근사적으로) 성립한다. 이 성질은 TD(0) Prediction으로도 가치 함수 를 추정할 수 있음을 보여준다. 구체적으로, 고정된 정책 에 대해, 가 다음 두 가지 중 하나인 경우 TD(0) Prediction을 이용하면 100%의 확률로 는 실제 가치 함수 로 수렴한다.
가 충분히 작은 상수이다.
은 다음 조건을 따르는, 감소하는 변수이다.
(단, 는 상수)
MC Prediction과 TD(0) Prediction 모두 를 실제 가치 함수 로 수렴시킬 수 있다면, 어느 방법이 더 빨리 수렴할까?(= 어느 방법의 학습 속도가 더 빠를까? = 어느 방법이 더 적은 데이터로도 더 효율적으로 학습할 수 있을까?) 사실 이 질문은 수학적으론 아직 답이 명확하게 증명되진 않았으나, 경험적으로 확률적인 문제(stochastic task)에서는 TD Method가 Constant- MC Method보다 더 빨리 수렴한다는 것이 알려져 있다.
각 에 대해, 0개의 에피소드를 보고 추정한 가치 함수의 RMS Error, 1개의 에피소드를 보고 추정한 가치 함수의 RMS Error, ..., 100개의 에피소드를 보고 추정한 가치 함수의 RMS Error를 계산한다.
6의 과정을 100번 반복한다. 즉, 100개의 에피소드를 보는 학습을 처음부터 100번 반복한다.
각 에 대해, 7의 결과를 평균한다. 즉, 0개의 에피소드로 계산한 RMS Error 100개의 평균, 1개의 에피소드로 계산한 RMS Error 100개의 평균, ... 100개의 에피소드로 계산한 RMS Error 100개의 평균을 구한다. 이를 그래프로 나타낸 것이 Fig.04이다.
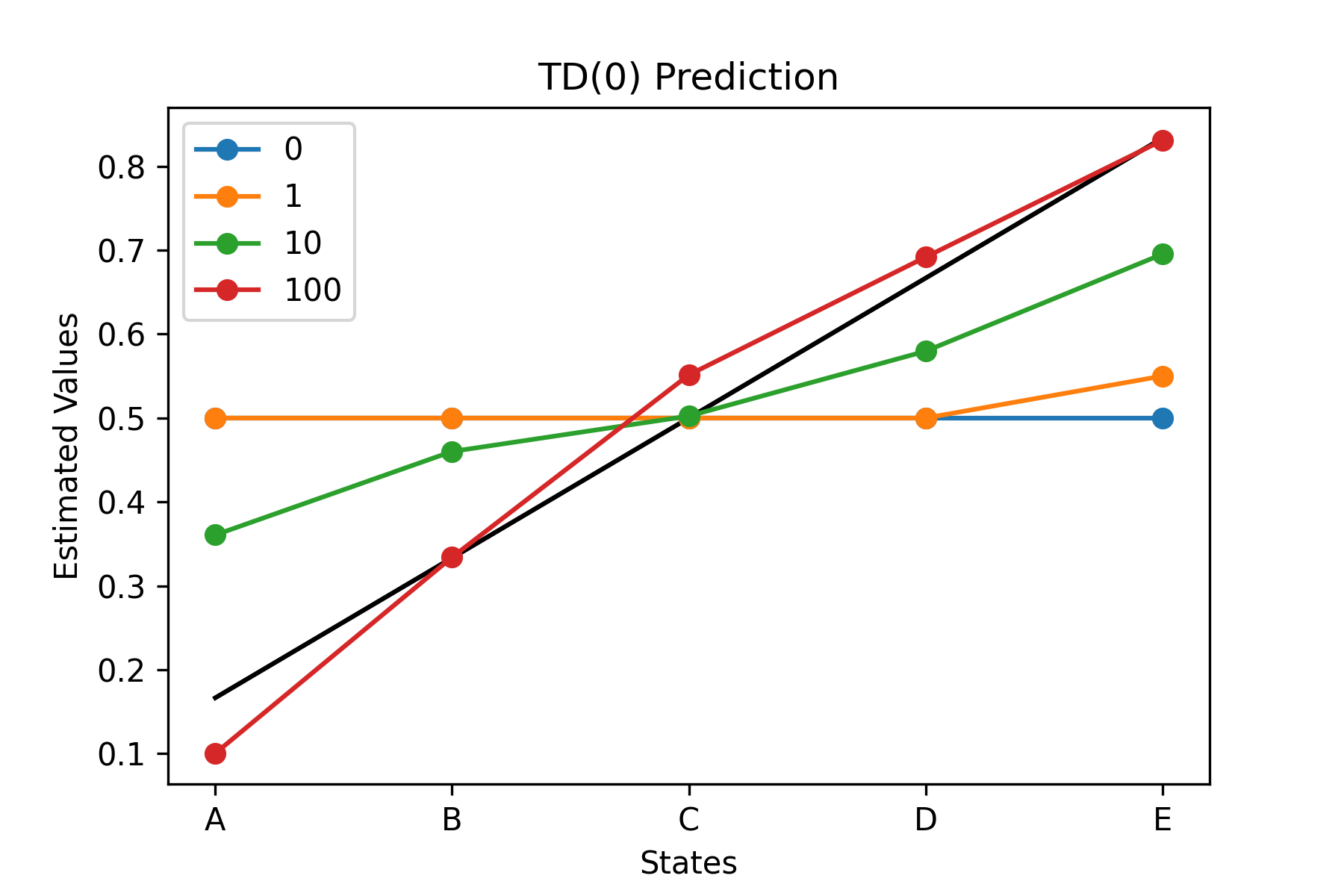
Fig.02 Random Walk - TD(0) Prediction
TD(0) Prediction을 이용해 가치 함수를 추정한 결과. 검은 선은 참값(true values)을 나타낸다.
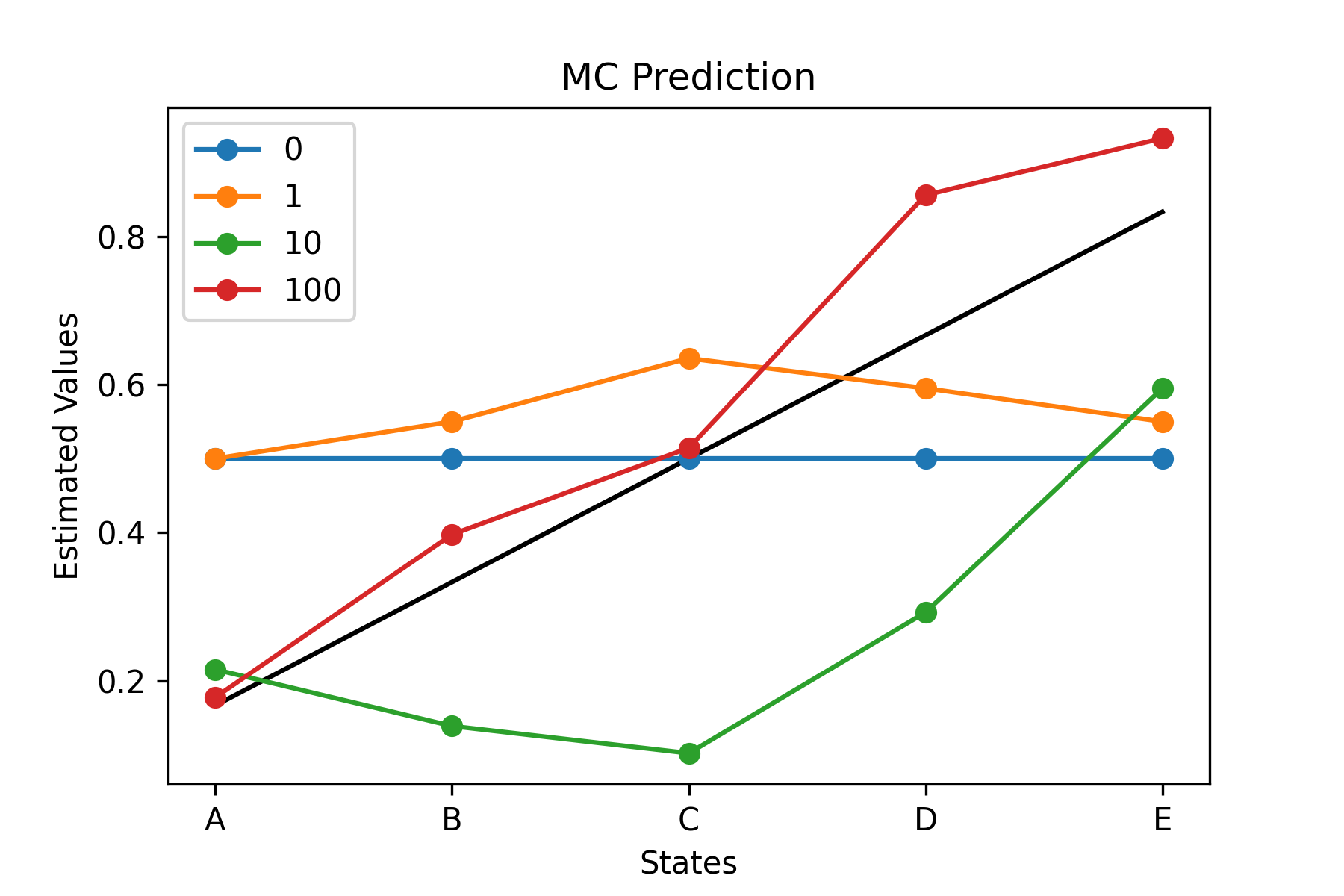
Fig.03 Random Walk - MC Prediction
MC Prediction을 이용해 가치 함수를 추정한 결과. 검은 선은 참값(true values)을 나타낸다.
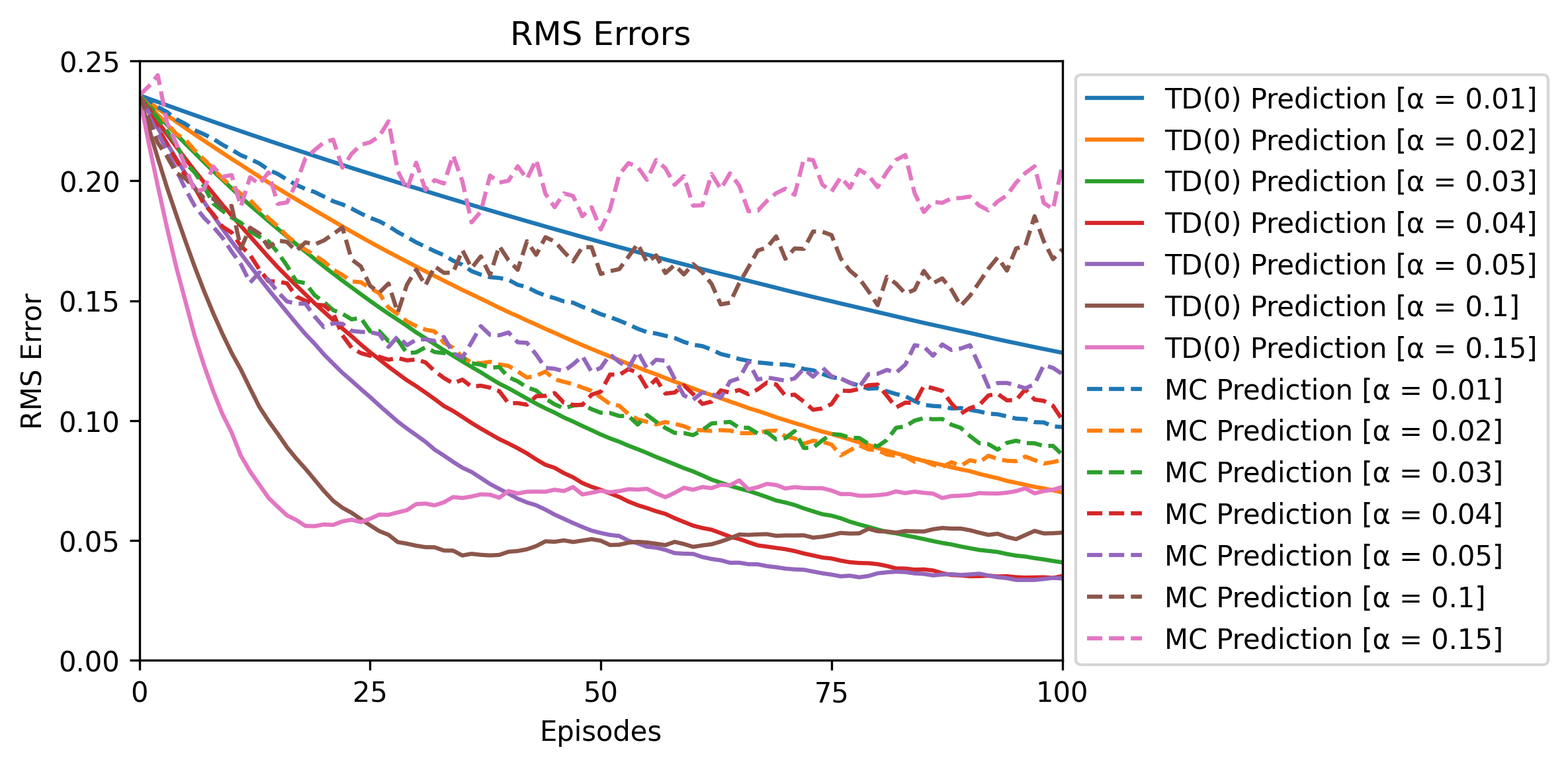
Fig.04 Random Walk - RMS Errors
각 에 대해, TD(0) Prediction과 MC Prediction로 추정한 가치 함수에 대해 RMS Error를 계산한 결과. x축은 사용한 에피소드의 개수를, y축은 RMS Error를 의미한다. 실선은 TD(0) Prediction, 점선은 MC Prediction을 의미한다. 같은 색은 같은 를 의미한다.
Fig.02, Fig.03에서 볼 수 있듯이, 에피소드의 개수가 많아짐에 따라 가치 함수의 추정값은 점점 더 참값(검은 실선)에 가까워진다.[6] 이때 Fig.04에서 볼 수 있듯이, TD(0) Prediction이 MC Prediction에 비해 더 적은 오류(RMS Error)를 가진다.[7]
TD(0) Method를 이용하여 Control 문제를 풀어보자. TD Method로 Control 문제를 푸는 기본적인 아이디어는 GPI이다. 다만 이번엔 TD Prediction을 이용해 Evaluation 과정을 수행한다.
TD Control의 해법에는 On-policy[8] TD Control 방법인 SARSA, 그리고 Off-policy[9] TD Control 방법인 Q-Learning, 이렇게 두 가지가 있다. 두 방법 모두 상태-가치 함수(state-value function) 가 아닌, 행동-가치 함수 를 사용해 학습을 진행한다.
On-policy TD Control Method를 SARSA라 부른다. SARSA에서는 다음 업데이트 식을 이용해 행동-가치 함수(action-value function) 를 업데이트한다.
SARSA는 위 업데이트 식을 이용해 현재 정책 에 대해 를 추정하고, 동시에 정책 를 에 대해 탐욕적인 정책이 되게 바꾼다. 참고로, SARSA라는 이름은 위 업데이트 식에서 사용하는 5개 값, , , , , 를 따 만들어졌다. 만약 모든 상태-행동 쌍(state-action pair)이 무한 번 방문되고(visit), 무한한 시간이 지난 후 정책이 Greedy Policy로 수렴하면,[10] SARSA는 100%의 확률로 최적 정책 와 최적 가치 함수 로 수렴한다.
On-policy TD Control Method를 Q-Learning이라 부른다. Q-Learning은 다음 업데이트 식을 이용해 행동-가치 함수(action-value function) 를 업데이트한다.
, , , , 를 사용하는 SARSA 업데이트 식과는 다르게 Q-Learning의 업데이트 식은 , , , 만 사용한다. 이 업데이트 식을 적용하면 현재 정책이 무엇이든 는 항상 최적 행동-가치 함수 으로 수렴하게 된다. 물론 이 수렴성을 보장하려면 (여느 Off-policy Control 방법에서처럼) 모든 상태-행동 쌍에 대해 가 업데이트되어야 한다.
참고로 Q-Learning에서 Q는 Quality의 약자이다. Q-Learning은 현재 상태에서 어떤 행동을 하는 것이 가장 Quality가 좋은지를(= 가장 큰 행동-가치(action-value)를 가지는지 = 가장 높은 보상(reward) 기댓값을 가지는지) 계산하므로 이런 이름이 붙었다.
Pseudo Code : Q-Learning (-greedy Policy 사용)
모든 , 에 대해, 을 임의의 값으로 초기화. 단, .
Loop for each episode:
를 임의의 상태 으로 초기화
Loop for each step of episode:
현재 에 대해 -greedy Policy를 사용하여 에서의 행동 를 선택 // Improvement 과정
시행하고, 보상 과 다음 상태 관측
// Evaluation 과정
until is terminal
위 의사 코드를 보면, 목표 정책(를 이용한 Greedy Policy)과 행동 정책(-greedy Policy)이 다르다. 따라서 Q-Learning은 Off-policy Method이다.
(Env._getStateIdx() 메소드로 인해) 하나의 숫자로 된 상태를 [x, y] 꼴로 바꾼다.
line 83 ~ 85 : Control._getAction() 메소드
0, 1, 2, 3 형태로 되어 있는 행동을 각각 "up", "down", "left", "right" 꼴로 바꾼다.
line 88 ~ 89 : Control.learn() 추상 메소드
line 91 ~ 113 : Control.test() 메소드
현재 (Control.learn() 메소드로) 학습된 Q에 따라 Greedy Policy로 에피소드를 생성하는 메소드
verbose 매개변수에 True가 주어지면 행동에 "up", "down", "left", "right"가 들어가고, verbose에 False가 주어지면 0, 1, 2, 3이 들어간다. 아무 값도 주지 않으면 기본값으로 False가 사용된다.
line 115 ~ 140 : SARSA 클래스
line 116 ~ 140 : SARSA.learn() 메소드
SARSA로 학습을 진행하는 메소드
episode_num개의 에피소드를 이용해 학습을 진행한다.
is_from_scratch 매개변수에 True를 주면 Q를 초기화하고 처음부터 학습을 진행한다. 기본값은 False이다(즉, 현재 Q 값을 초기화하지 않고 계속해서 학습을 이어나간다).
각 에피소드에서 받은 총 보상들의 배열을 반환한다.
line 142 ~ 165 : QLearning 클래스
line 143 ~ 140 : QLearning.learn() 메소드
QLearning으로 학습을 진행하는 메소드
episode_num개의 에피소드를 이용해 학습을 진행한다.
is_from_scratch 매개변수에 True를 주면 Q를 초기화하고 처음부터 학습을 진행한다. 기본값은 False이다(즉, 현재 Q 값을 초기화하지 않고 계속해서 학습을 이어나간다).
각 에피소드에서 받은 총 보상들의 배열을 반환한다.
line 167 ~ 202 : drawEpisode() 함수
(Control.test()로 생성된) episode를 받아 이를 그림(Fig.06)으로 그려주는 함수
line 204 ~ 214 : drawGraph() 함수
(SARSA.learn()과 QLearning.learn()으로 생성된) 에피소드별 보상들의 배열을 그래프(Fig.07)로 그려주는 함수
line 216 ~ 227 : main
line 220 : sarsa_reward_sums는 500개의 에피소드를 이용해 SARSA로 학습하는 과정을 100번 반복해 얻은, 100개의 에피소드별 보상들의 배열들을 평균해 구한다.
line 224 : qlearning_reward_sums는 500개의 에피소드를 이용해 Q-Learning로 학습하는 과정을 100번 반복해 얻은, 100개의 에피소드별 보상들의 배열을 평균해 구한다.
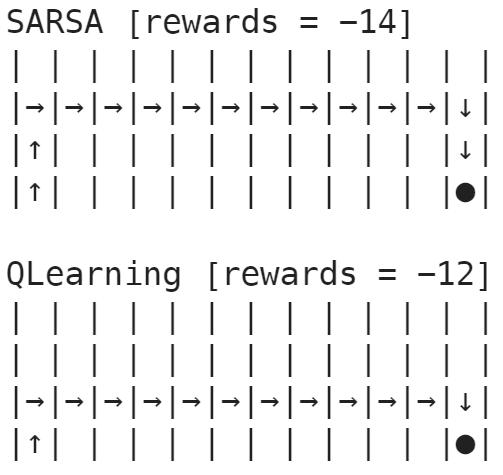
Fig.06 Cliff Walking - 학습 결과
500개의 에피소드를 이용해 SARSA와 Q-Learning로 학습한 결과
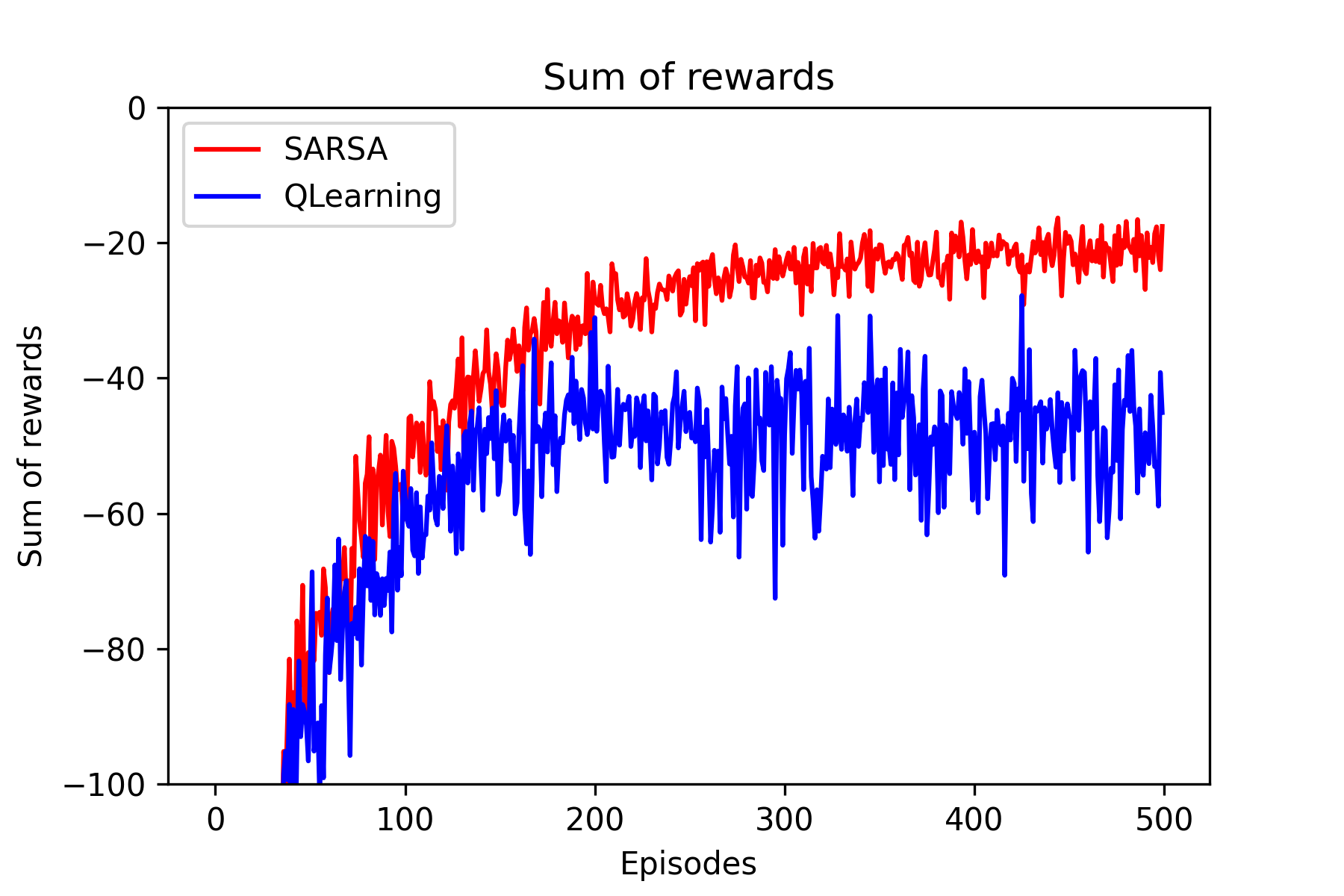
Fig.07 Cliff Walking - 각 에피소드에서 받은 보상의 합
500개의 에피소드를 이용해 SARSA와 Q-Learning로 학습하는 과정을 100번 반복해 얻은, 100개의 에피소드별 보상의 배열들의 평균을 그래프로 나타내었다. 빨간 색은 SARSA를, 파란 색은 Q-Learning을 의미한다.
Fig.06에서 볼 수 있듯이, Q-Learning으로 구한 정책은 절벽(cliff)에 딱 붙어서 가는, 최적 정책(optimal policy)이다. 그러나 학습 과정에서 행동 정책(-greedy Policy)으로 다음 행동을 결정하면 간간히 절벽으로 떨어질 수 있다. 반면 목표 정책과 행동 정책이 같은 SARSA로 구한 정책은 절벽에서 한 칸 떨어진, (최적 정책은 아니지만) 조금 더 '안전한' 정책이다. 이렇게 보면 Q-Learning이 최적 정책을 찾았으므로 조금 더 좋아 보이겠지만, Fig.07을 보면 학습 중 성능(online performance)은 SARSA(빨간 색)가 Q-Learning(파란 색)보다 더 낫다는 것을 볼 수 있다. SARSA는 Q-Learning에 비해 조금 더 안전한 방향으로 학습이 진행되므로, 학습 과정에서 절벽에 떨어지는 경우가 적어 학습 중 성능이 더 잘 나온 것이다.
참고로 만약 이 시간이 지남에 따라 점점 줄어든다면,[11] SARSA와 Q-Learning 둘 다 (Q-Learning으로 구한 것과 같은) 최적 정책으로 수렴하게 된다.
Q-Learning의 업데이트 식에서, 다음 상태 에서의 모든 가치 중 최대값()을 사용하는 대신, 다음 상태 에서 현재 정책 을 따를 때 받을 수 있는 가치들의 기댓값()을 사용하는 다음 업데이트 식을 생각해보자.
이 업데이트 식은 SARSA가 를 움직일 것으로 기대(expectation)되는 방향으로 를 움직인다. 그래서 이 업데이트 식을 사용하고, 나머지 부분에서는 Q-Learning과 동일한 방식으로 하는 Control 방법을 Expected SARSA라 한다.
Pseudo Code : Expected SARSA (-greedy Policy 사용)
모든 , 에 대해, 을 임의의 값으로 초기화. 단, .
: -greedy Policy
Loop for each episode:
를 임의의 상태 으로 초기화
Loop for each step of episode:
현재 에 대해 를 사용하여 에서의 행동 를 선택
시행하고, 보상 과 다음 상태 관측
until is terminal
Expected SARSA는 (당연히) SARSA보다 계산의 복잡도가 높지만, SARSA에서 무작위[12]로 다음 동작 을 뽑음으로 인해 발생하는 분산(variance)이 없다. 따라서 같은 양의 경험(experience)으로 학습을 시켜보면 대부분의 경우 Expected SARSA가 SARSA보다 성능이 좋다. 특히 Expected SARSA는 SARSA와 다르게 큰 를 사용해도 최적 정책 및 최적 가치 함수로 수렴시킬 수 있다. 위 Cliff Walking 예제를 예를 들면, 각 상태에서의 행동은 결정론적이므로(deterministically)[13] 이 예제에서의 무작위성은 오직 정책에서만 나온다. 따라서 Cliff Walking에서는 로 놓고 Expected SARSA를 적용해도 아무런 문제가 없다.[14]
위에서 설명한 Expected SARSA는 목표 정책과 행동 정책이 같은 On-policy Method였지만, 사실 Expected SARSA는 목표 정책과 행동 정책을 다르게 해 Off-policy Method로 사용할 수도 있다. 예를 들어 를 Greedy Policy로 설정하고, 현재 상태 에서 다음 행동 를 만들어내는 행동 정책으로 적당히 탐색적인(exploratory) 정책을 사용하면(ex. -greedy Policy) Expected SARSA는 Q-Learning과 완벽히 동일해진다. 이 관점에서 보면 Expected SARSA는 Q-Learning을 포함한다고 할 수 있다. 약간의 추가적인 계산 비용을 감수할 수만 있다면, Expected SARSA는 TD Control 방법들 중 가장 우수한 방법이다.
각 에피소드마다 상태 A에서 left를 선택했는지 안 했는지를 담은 배열 left_actions를 반환
ex. 3개의 에피소드를 살펴볼 때(= episode_num=3), 첫 번째 에피소드에서는 상태 A에서 left를, 두 번째 에피소드에서는 right를, 마지막 에피소드에서는 left를 선택해 수행했다면 [1, 0, 1]을 반환
이 반환값은 drawGraph() 함수에서 사용됨
line 80 ~ 116 : DoubleQLearning 클래스
line 89 ~ 91 : DoubleQLearning._argmax() 메소드
인자로 주어진 1차원 배열 array에서, 최대값의 인덱스를 반환
만약 최대값이 여러 개 있다면 그 중 랜덤한 인덱스를 반환
line 93 ~ 116 : DoubleQLearning.learn() 메소드
각 에피소드마다 상태 A에서 left를 선택했는지 안 했는지를 담은 배열 left_actions를 반환
ex. 3개의 에피소드를 살펴볼 때(= episode_num=3), 첫 번째 에피소드에서는 상태 A에서 left를, 두 번째 에피소드에서는 right를, 마지막 에피소드에서는 left를 선택해 수행했다면 [1, 0, 1]을 반환
이 반환값은 drawGraph() 함수에서 사용됨
line 118 ~ 130 : drawGraph() 함수
Fig.09의 그래프를 그리는 함수
x축은 살펴본 에피소드의 개수를, y축은 10,000개의 에이전트 중 left 행동을 수행한 에이전트의 비율을 나타낸다.
점선은 left 또는 right가 -greedy Policy 하에서 최대로 실행될 수 있는 빈도인 5%와 95%를 나타내고 있다.
line 132 ~ 139 : main
line 137, 138 : 10,000개의 에이전트를 각각 300개의 에피소드로 학습을 시키고, 학습 과정에서 left 행동이 어떤 비율로 수행되었는지를 계산
Fig.09 Maximization Bias Example - 학습 결과
x축은 살펴본 에피소드 개수를, y축은 10,000개의 에이전트 중 left 행동을 수행한 에이전트의 비율을 나타낸다. 점선은 left 또는 right가 -greedy Policy 하에서 최대로 실행될 수 있는 빈도인 5%와 95%를 나타내고 있다.
상태 A에서 left를 수행했을 때의 Return의 기댓값은 -0.1이고 right를 수행했을 때의 기댓값은 0이므로, 최적 정책은 A에서 right를 선택해야 한다. 그러나 Fig.09에서 볼 수 있듯이 학습 초기에 Q-Learning(파란색 그래프)은 오히려 left를 더 많이 하는 방향으로 학습되는 것을 볼 수 있다. 왜 이런 일이 발생했을까?
Q-Learning의 업데이트 식을 살펴보자.
위 식에서, 빨간색 테두리 영역의 정확도가 높아질수록 추정의 정확도도 같이 높아진다. 이때 빨간색 테두리 영역의 참값은 실제 가치 함수 를 사용한, 이다. 즉 빨간색 테두리 영역에는 , 또는 하다못해 전체에 대한 추정값이 들어가는 것이 좋다. 그러나 우리는 도 모르고 의 추정값도 모르기에, 그 대신 가치의 추정값()들에 대한 최대값 를 사용했다. 다시말해 "가치들의 최대값에 대한 추정값(estimate of the maximum value)"을 써야할 때 그 대신 "가치의 추정값들에 대한 최대값(maximum over estimated values)"을 사용한 것이다.
어떤 상태에서 행동들을 했을 때 정규분포 에 따른 보상을 받는다는 말은, 원래 받을 보상은 이지만 환경의 불확실성(uncertainty) 때문에 만큼의 분산(variance)이 생긴다는 말이다. 위 예제로 다시 돌아가보자. 상태 B에서 행동을 수행하면 정규분포 에서 무작위로 추출한 보상(= 가치)을 받는다는 말은, 상태 B에서 가능한 모든 행동 에 대해 이라는 뜻이다. 따라서 이 된다.
하지만 Q-Learning 업데이트 식에서는 대신 를 쓴다. 정규분포 을 따르는 보상은 몇몇은 양수일 것이고, 몇몇은 음수일 것이다.[15] 이 때문에 몇몇 행동들의 는 양수가 될 것이고, 몇몇 행동들의 는 음수가 될 것이다. 따라서 이들에 대해 를 계산하면 (-0.1이 아닌) 양수가 나온다. 즉, 편향(bias)이 발생한 것이다. 그리고 이 편향은 left 행동이 right 행동보다 더 좋다고 에이전트가 '착각'하게 만든다.
이런 식으로 최대값 연산을 할 때 "가치들의 최대값에 대한 추정값" 대신 "가치의 추정값들에 대한 최대값"을 사용하여 발생하는 편향을 최대화 편향(Maximiaztion Bias) 이라 한다. 우리가 이때까지 살펴본 TD Control 기법들에는 모두 최대값을 계산하는 부분이 있었다.[16] 따라서 이 모든 기법들에는 다 최대화 편향이 존재한다.
최대화 편향은 결정론적인 환경(deterministic environment)에서는 큰 문제가 되지 않는다. 하지만 위 예제와 같은 확률론적인 환경(stochastic environment)에서는 학습 속도와 성능에 부정적인 영향을 끼칠 수 있다. 실제로 Fig.09에서 볼 수 있듯이, Q-Learning으로 학습시킨 에이전트(파란색)는 학습 초기에 left를 더 많이 수행한다. 그리고 학습이 진행되며 left의 가치가 점점 더 정확히 추정되고 나서야 left의 선택 비율은 줄어든다.
그러면 어떻게 하면 최대화 편향을 피할 수 있을까? 최대화 편향은 사실 TD Method의 Bootstrapping 과정에서 최적 행동()을 결정하는 과정과 해당 최적 행동의 가치를 추정하는 과정에서 같은 샘플(에피소드)을 사용하기 때문에 발생한다. 그러므로 이 두 과정에서 다른 데이터를 사용하면 최대화 편향을 피할 수 있다.
이를 위한 한 가지 방법이 Double Learning이다. Double Learning은 아이디어는 두 개의 행동-가치 함수(action-value function) , 를 사용하는 것이다. 특정 상태 에서의 최적 행동 을 결정할 때는 둘 중 한 정책(이라 하자)을 결정하고,[17] 결정된 최적 행동의 가치를 계산할 때는 다른 정책()를 이용한다.[18]
학습을 진행하면서 과 의 역할을 무작위로 계속 바꿔가며 학습하면[19]과 모두 참값 로 수렴하게 만들면서도 최대화 편향을 피할 수 있게 된다. Double Learning은 두 개의 행동-가치 함수를 사용하므로 메모리 사용량이 2배로 늘어난다는 단점이 있지만, 에피소드 하나에 대해 하나의 행동-가치 함수만 학습되므로 (최대화 편향을 없애면서도) 학습 시간이 증가하지는 않는다는 장점이 있다.
이전 글에서 살펴봤던 tic-tac-toe 게임을 다시 생각해 보자. 우리가 이때까지 보았던 TD Control 기법들은 모두 행동-가치 함수(action-value function)을 사용했었다. 그런데 이전 글에서 tic-tac-toe 게임의 인공지능을 만드는 방법을 간략히 설명할 때는 마치 상태-가치 함수(state-value function)을 쓰는 것처럼 설명했었다.
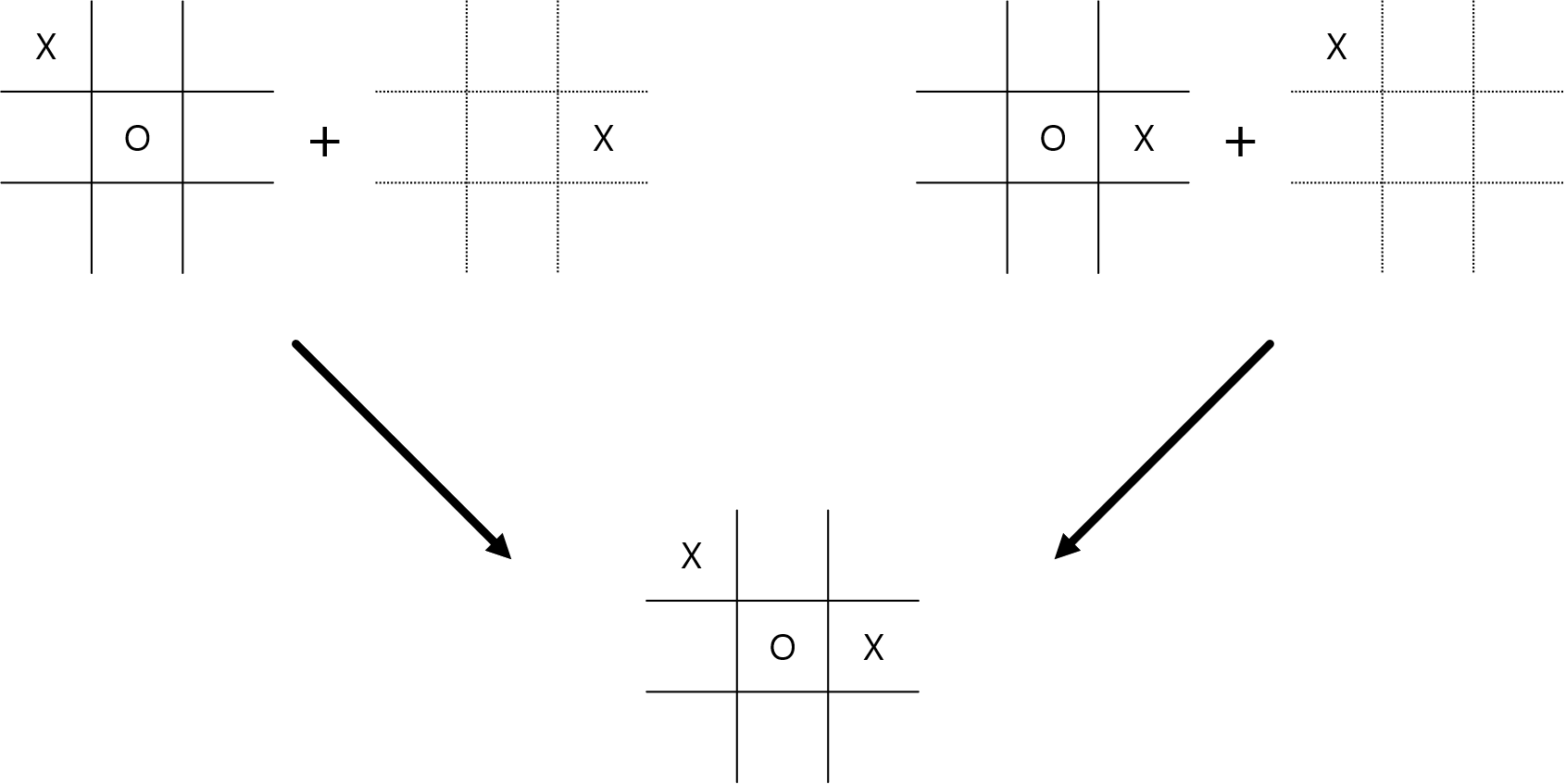
사실 tic-tac-toe 게임을 만들 때 쓰는 가치 함수는 그냥 상태-가치 함수가 아닌, 다음-상태-가치 함수(afterstate value function)라 불리는 가치 함수이다. 이 가치 함수는 에이전트가 행동을 수행해 전이되는 '다음 상태(afterstate)'의 가치를 반환하는 함수이다. 잘 생각해 보면, tic-tac-toe 게임에서는 다른 상태에서 다른 행동을 하더라도 같은 상태로 전이할 수 있다.
Fig.10 Tic-tac-toe
tic-tac-toe 게임에서는 다른 상태에서 다른 행동을 해도 동일한 '다음 상태(afterstate)'로 전이할 수 있다.
이런 tic-tac-toe 게임을 행동-가치 함수를 이용해 푼다면 (물론 못 풀 것은 없지만) 쓸데없이 메모리를 많이 사용하게 되고 또 학습 속도가 아주 느려진다. 하지만 다음-상태-가치 함수를 사용하면 아주 효율적인 학습이 가능하다.
이처럼 다음-상태-가치 함수는 tic-tac-toe 게임과 같이 에이전트의 행동으로 전이할 다음 상태를 확실히 아는 결정론적인 환경(deterministic environment)에서 유용하다. 그렇다고 환경에 대한 전체 정보(ex. 전체 dynamics function)를 알아야만 다음-상태-가치 함수를 쓸 수 있는건 아니다(당장 tic-tac-toe 게임만 해도 상대방의 다음 행동이 무엇일지는 모른다). 다음-상태-가치 함수는 게임 이외에도 순서 정하기 문제(queing tasks) 등에서도 쓸 수 있다.
예를 들어, (2, 3) 칸에서 "up" 행동을 하면 무조건 (3, 3) 칸으로 이동한다. 결정론적인 행동의 반댓말은 확률론적(stochastic)인 행동이다. 확률론적인 행동의 예는 (2, 3) 칸에서 "up"을 했을 때 70% 확률로 (3, 3) 칸, 30%의 확률로 (2, 2) 칸으로 이동하는 행동 등이 있다. ↩︎
반면 SARSA의 경우 작은 를 사용해야 하므로, 많은 수의 경험으로 오랜 시간 학습시켜야 한다. ↩︎
SARSA, Expected SARSA에서는 -greedy Policy를 많이 사용하는데, -greedy Policy를 만들면서 최대값 연산을 수행한다. Q-Learning에서는 (위에서 살펴본 것처럼) 최대값 연산이 들어 있는 업데이트 식을 이용해 가치 함수를 업데이트하고, 이 가치 함수에 대해 Greedy Policy를 만들면서 또 최대값 연산을 수행한다. ↩︎



Comments