DP(Dynamic Programming)란?
알고리즘을 공부해 보았다면 DP(Dynamic Programming, 동적 계획법)에 대해 들어보았을 것이다. 알고리즘에서의 DP는 다음 두 가지 속성을 가지고 있는 문제에 적용 가능한 풀이 방법이다.
- Overlapping Subproblem : 문제는 여러 개의 하위 문제(subproblem)으로 쪼갤 수 있다. 이때 하위 문제들은 서로 겹치는(overlapping) 부분들이 있어, 한 하위 문제를 풀 때 사용했던 결과를 적당한 곳에 저장해 놨다가[1] 재활용할 수 있다.[2]
- Optimal Substructure : 하위 문제의 최적 해(optimal solution)를 이용해 상위 문제의 최적 해를 구할 수 있다.[3]
Finite MDP 상황에서, 환경에 대해 완벽한 지식이 주어진 경우 DP를 이용하면 최적 정책(optimal policy)을 정확히 구할 수 있다.
그러나 안타깝게도 DP는 한계가 분명하다.
- Finite MDP가 아닐 경우 DP를 사용할 수 없다.
- Finite MDP이더라도 환경에 대해 완벽한 지식을 모른다면 DP를 사용할 수 없다.
- 계산 시간이 엄청나게 많이 필요하다.
이런 이유들 때문에 RL 문제에 DP를 범용적으로 적용하긴 어렵다. 그러나 많은 RL 풀이법들이 DP의 아이디어를 사용하기에 DP를 잘 이해하는 것이 중요하다.
Policy Iteration
첫 번째로 배울 DP는 Policy Iteration이라는 방법이다. Policy Iteration을 이용하면 최적 정책을 찾을 수 있다. 참고로 이렇게 최적 정책을 찾는 문제를 Control 문제라 한다.
Policy Iteration을 간단히 설명하면 다음과 같다.
- Initialization : 정책
, 상태-가치 함수 를 적당한 값으로 초기화한다. - Policy Evaluation : 현재 정책
를 적용했을 때 각 상태 의 가치 를 업데이트한다. - Policy Improvement : 업데이트된 가치 함수
를 바탕으로 현재 정책 보다 조금 더 개선된 새로운 정책 를 만든다. 이를 현재 정책으로 삼는다. - 2, 3번 과정을 여러 번 반복한다.
Policy Evaluation 과정과 Policy Improvement 과정을 번갈아가며 수행하면 가치 함수와 정책이 점점 최적 가치 함수
여기서 빨간 화살표는 Policy Evaluation을, 파란 화살표는 Policy Improvement를 의미한다. 각 과정을 자세히 살펴보자.
Policy Evaluation
Policy Evaluation은 임의의 정책
우린 환경에 대한 모든 정보를 알고 있으므로, 이전 글에서 살펴본 Bellman equation을 세울 수 있다. 각 상태에 대해 Bellman equation을 만들면, 우리는
선형대수학 등에서 학습한 연립 선형방정식을 푸는 다양한 기법들을 활용하면 이 연립방정식을 풀 수 있다. 하지만 이 방법은 상태의 수가 많아지면 많이질수록 계산 난이도가 매우 올라간다는 단점이 있다. 그래서 일반적으론 이 방법보다는 Iterative policy evaluation이라는 방법을 이용해 연립방정식을 푼다. Iterative policy evaluation은 Bellman equation의 재귀성을 이용해 수치해석적으로(numerically) Bellman equation을 푸는 방법이다. Iterative policy evaluation의 알고리즘은 다음과 같다.
각 상태
에 대해, 를 임의의 값으로 초기화한다. 다음 업데이트 식을 이용해 반복적으로(iterative) 각 상태
마다 를 업데이트한다.[5] 2를 적당한 횟수만큼 반복한다.
Iterative policy evaluation을 수행하면 수열
여담: Iterative policy evaluation 구현하기
Iterative policy evaluation을 구현하는 가장 직관적은 방법은 두 개의 배열을 사용해, 각각 옛 값(
그런데 배열을 하나만 쓰는 방법도 있다. 업데이트 할 때, 최신 값이 옛 값을 그냥 덮어씌우게 하는 것이다.[6] 얼핏 생각해 보면 이렇게 할 경우 몇몇
그리고 또 하나 생각해 봐야 할 것이, 반복을 멈추는 시점이다. 수학적으로는
를 업데이트할 때 각 상태별로 최신 값과 옛 값의 차 를 계산해, 그 중 최댓값을 찾는다. - 만약 그 최댓값이 특정 값(threshold) 이하로 떨어지면 그만둔다.
Policy Improvement
Policy Improvement는 Policy Evaluation으로 계산된 최신 가치 함수
우리는 이전 글에서
가 성립한다고 해 보자.[7] 그렇다면 상태
이를 일반화하면 다음과 같이 된다.
Policy Improvement Theorem
결정론적 정책
가 성립하면, 정책
증명 : Policy Improvement Theorem
이제 얘기를 조금 더 확장해 하나의 상태에서만 개선된 정책이 아닌, 전체 상태에 대해 더 개선된 정책
만약 Policy Improvement로 만든 새로운 정책
이때, 위 식의 형태는 이전 글에서 다룬 Bellman optimality equation과 같음을 볼 수 있다. Finite MDP 문제에서는 Bellman optimality equation의 해가 유일하므로,
이때까지의 우리의 논의는 모두 주어진 정책이 결정론적 정책일 때의 얘기였다. 그런데 Policy Improvement는 확률론적 정책(stochastic policy)으로도 쉽게 확장 가능하다. Policy Improvement Theorem은 확률론적 정책에 대해서도 적용된다. 만약 탐욕적인 행동(
구현
Policy Iteration에 대한 의사 코드(pseudo code)는 다음과 같다.
Pseudo Code : Policy Iteration (Iterative Policy Evaluation 사용)
1. Initialization
모든
2. (Iterative) Policy Evaluation
Loop:
Loop for each
until
3. Policy Improvement
policy_stable
Loop for each
old_action
If old_action
policy_stable
If policy_stable:
Return
else:
Goto 2. Policy Evaluation
Value Iteration
Policy Iteration의 문제점 중 하나는 Policy Evaluation에서
사실 Policy Evaluation 과정은 수렴성을 잃지 않으면서 더 짧게 요약될 수 있다. Value Iteration을 사용하면 단 한 번의 sweep만으로도(= 각 상태들이 한 번씩만 업데이트되어도) 최적 가치 함수를 찾을 수 있다. Value Iteration에서는 다음 업데이트 식을 이용하여 (요약된) Policy Evaluation과 Policy Improvement를 한 번에 수행한다.
이렇게 해도
Policy Evaluation 업데이트 식과 Value Iteration 업데이트 식은 아주 유사하다. 딱 하나 차이점이라면 Value Iteration 업데이트 식에는
Value Iteration 역시 Policy Evaluation에서와 마찬가지로 이론적으로는 무한 번 반복해야
구현
Value Iteration을 의사 코드로 나타내면 다음과 같다.
Pseudo Code : Value Iteration
모든
Loop:
Loop for each
until
Return
Asynchronous DP
이때까지 살펴본 DP(Policy Iteration, Value Iteration)의 문제점 중 하나는 매 반복(iteration)마다 상태 전체에 대해 연산을 수행해야 한다는 것이다. 이 방법들은 상태 수가 적을 때는 괜찮겠지만 상태 수가 너무 많아지면 계산 비용이 너무 많이 나오게 된다. Asynchronous DP는 여기서 착안한 DP 기법이다.[9] Asynchronous DP에서는 다른 상태들의 가치가 업데이트됐든 안 됐든 상관없이 매 반복에 오직 한 상태의 가치만 업데이트한다. 이 과정에서 몇몇 상태들의 가치는 여러 번 업데이트되기도 한다. 단
예를 들어 Value Iteration에 Asynchronous DP를 적용하게 되면, 각 반복 단계
물론 전체 상태에 대한 연산을 없애는 것이 반드시 계산량 감소를 의미하는 것은 아니다. Asynchronous DP가 시사하는 점은 정책을 당장 개선할 수 있는데도 전체 상태에 대한 무의미한 연산이 끝날 때까지 기다릴 필요가 없다는 것이다. 이 '유연함'을 이용하면 최적 정책을 더 빠르게 찾을 수 있다. 예를 들어 업데이트 순서를 적절히 조절하면, 가치가 상태 간에 효율적으로 전파되게(propagate) 할 수 있고, 자주 업데이트될 필요가 없는 가치들은 업데이트를 미룰 수도 있다. 만약 어떤 상태가 최적 행동(optimal behavior)와 전혀 관련이 없다면 해당 상태의 가치 업데이트를 아예 하지 않을 수도 있다. 이런 장점 덕분에 Asynchronous DP는 실시간 상호작용하는 RL 문제에 적용하기 좋다.
여담 : GPI (Generalized Policy Iteration)
앞에서 살펴본 DP들을 정리해 보자. Policy Iteration은 Evaluation 과정(Policy Evaluation)과 Improvement 과정(Policy Improvement)으로 이루어져 있다. Evaluation 과정은 현재 정책으로부터 가치를 계산하는 과정이고, Improvement 과정은 현재 가치로부터 최적화된 정책을 만들어내는 과정이다. Policy Iteration에서 Evaluation 과정과 Improvement 과정은 번갈아 가며 하나가 끝나면 다른 하나가 시작되는 식으로 되어 있다. 하지만 반드시 이래야만 하는 것은 아니다. Value Iteration에서는 Improvement 과정 사이에 Evaluation 과정이 한 번만(sweep) 시행된다. Asynchronous DP에서는 Evaluation 과정과 Improvement 과정이 더 긴밀하게 붙어 있다. 세부 사항은 각 알고리즘마다 조금씩 다르긴 하지만, 이 두 과정이 모든 상태들을 업데이트하면 일반적으로 최적 가치 함수와 최적 정책을 찾을 수 있다. 어찌됐건 Evaluation 과정과 Improvement 과정 간의 상호작용이 DP에서 매우 중요한 것을 볼 수 있다.
Evaluation 과정과 Improvement 과정 간의 이런 관계[11]를 GPI(Generalized Policy Iteration)라 부른다. 거의 모든 RL 풀이법들이 GPI를 사용한다. 즉 거의 모든 RL 풀이법이 정책과 가치 함수를 사용하고, 정책은 가치 함수에 대해 최적화되고(Improvement 과정) 가치 함수는 정책으로부터 유도된다(Evaluation 과정)는 것이다. Evaluation 과정과 Improvement 과정이 모두 안정화되면(stabilize) 정책과 가치 함수가 모두 최적화된 것이다.[12]
RL 문제에서, 정책이 주어졌을 때 이 정책에 대한 가치 함수를 계산하는 문제를 Prediction 문제라 하고, 최적 정책을 찾는 문제를 Control 문제라 한다. GPI에 의하면 Control 문제를 풀기 위해서는 Prediction 문제를 먼저 풀어야 한다. 우리가 앞으로 살펴볼 다른 RL 풀이법들에서는 따라서 Prediction 문제와 Control 문제를 푸는 방법들을 중점적으로 알아볼 것이다.
GPI에서의 Evaluation 과정과 Improvement 과정은 일종의 협력/경쟁 과정이라 볼 수 있다. 일반적으로 Evaluation 과정을 거치면 현재 정책이 탐욕적이지 않게 되고, Improvement 과정을 거치면 현재 가치 함수가 부정확하게 된다. 하지만 장기적인 관점에서 이 둘은 공통의 목표(최적 정책, 최적 가치 함수 찾기)를 향해 협력한다.
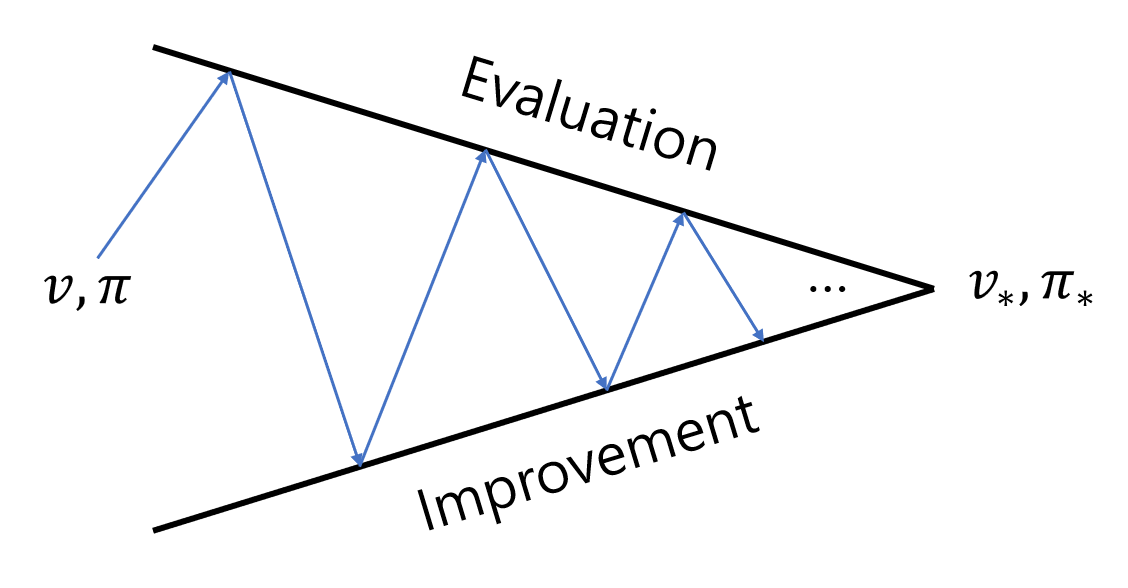
Fig.01 Evalution 과정과 Improvement 과정
일반적으로 Evaluation 과정을 거치면 현재 정책이 탐욕적이지 않게 되고, Improvement 과정을 거치면 현재 가치 함수가 부정확하게 된다. 하지만 장기적인 관점에서 이 둘은 공통의 목표(최적 정책, 최적 가치 함수 찾기)를 향해 협력한다.
여담 : DP의 효율성
위 문단에서 설명한 것처럼 DP는 큰 문제에 적용하기 힘든 것 등 한계가 많다. 하지만 MDP 문제를 푸는 다른 방법과 비교했을 때 사실 꽤 효율적인 방법이다. 다른 몇 가지 기술적인 문제들을 무시하면, DP로 최적 행동을 찾는 작업은 최악의 경우 다항 시간 복잡도를 가진다. 상태의 수가
LP(Linear Programming, 선형 계획법)를 이용해 MDP 문제를 풀 수도 있지만, 이는 DP보다 더 효율이 안좋다. 물론 몇몇 경우엔 DP보다 효율이 좋긴 하지만, 일반적으로 상태의 수가 조금만 많아져도 (DP는 풀 수 있지만) LP로는 계산이 불가능해진다. 현실적으로 큰 문제에서는 DP만 유일하게 적용 가능하다.
사실 일반적으론 DP를 써도 최악의 경우에서의 시간 복잡도보다 더 빨리 수렴한다. 초기값을 적절히 설정하는 등의 기법을 이용하면 더 빠르게 수렴시킬 수도 있다. 만약 상태의 수가 너무 많다면 Asynchronous DP를 사용하면 된다.
여담 : Bootstrapping
DP에서 각 상태의 가치 추정값은 다음 상태의 가치 추정값을 기반으로 업데이트된다. 이런 식으로 어떤 추정값을 다른 추정값을 기반으로 업데이트하는 것을 Bootstrapping이라 한다. 사실 많은 RL 풀이법들이 Bootstrapping을 사용한다.[13] DP처럼 환경에 대한 완벽하고 정확한 모델이 없어도 말이다.
이를 메모이제이션(Memoization)이라 한다. ↩︎
예를 들어, "
번째 피보나치 수를 구하는 문제"는 " 번째 피보나치 수를 구하는 하위 문제"와 " 번째 피보나치 수를 구하는 하위 문제"로 쪼갤 수 있다. 다시 " 번째 피보다치 수를 구하는 문제"는 " 번째 피보나치 수를 구하는 하위 문제"와 " 번째 피보나치 수를 구하는 하위 문제"로 쪼갤 수 있다. 이런 식으로 계속 하위 문제로 쪼개어 나갈 때, 몇몇 부분들이 겹치는 것을 볼 수 있다. 예를 들어, " 번째 피보나치 수를 구하는 하위 문제"는 " 번째 피보나치 수를 구하는 문제"의 하위 문제이면서 동시에 " 번째 피보나치 수를 구하는 문제"의 하위 문제이다. 이런 경우 동적 계획법에서는 번째 피보나치 수를 한 번만 계산해 (어딘가에 저장해 뒀다가(메모이제이션)) 이를 다시 재활용하여 사용한다. ↩︎ 예를 들어, A 도시에서 B 도시까지 가는 길찾기 문제가 있다고 해 보자. 만약 A 도시와 B 도시 사이 C 도시가 있다면, A 도시에서 B 도시까지 가는 최적 경로에는 A 도시에서 C 도시까지 가는 최적 경로와 C 도시에서 B 도시까지 가는 최적 경로들의 조합이 반드시 포함되어 있을 것이다. 이런 식의 성질을 Optimal Substructure라 한다. ↩︎
들 (단, ) ↩︎ 잘 보면 상태
의 가치 는 가능한 모든 다음 상태 들의 가치 들을 이용해 업데이트되고 있다. 이렇게 가능한 모든 다음 값들을 이용해 현재 값을 업데이트하는 것을 expected update라 부른다. "expected"라는 표현은 이 업데이트 과정이 샘플링(sampling)된 다음 상태 하나만을 보고 업데이트하는 것이 아닌, 가능한 모든 다음 상태들의 기댓값(expectation)을 구한다는 것에서 나온 표현이다. DP에서는 환경에 대한 모든 정보를 알고 있으므로 expected update가 가능하다. 참고로 다음 글에서 살펴볼 MC Method나 TD Method에서는 샘플링된 다음 상태 하나만을 이용해 업데이트가 진행된다(이를 sample update라 부른다). ↩︎ 이 방법에서의 매 업데이트는 전체 상태 공간(state space)을 한 번 쭉 훑으며(sweep) 진행되기에, 업데이트 한 번을 sweep이라 부르기도 한다. 즉 다음과 같이 말할 수 있다 : "Policy Evaluation은 여러 번의 sweep을 통해 현재 정책에 대한 가치 함수를 추정한다". ↩︎
이를 말로 풀어 쓰면 다음과 같다: 상태
에서 ( 가 아닌) 행동 를 시행하고 이후 를 따르는 것이, 계속 를 따르는 것보다 낫다. ↩︎ 결정론적 정책에서는 이런 경우 여러 행동 중 하나를 랜덤하게 고른다(어떤 것을 골라도 최적 행동이 된다). ↩︎
이에 반해, 앞에서 배웠던 Policy Iteration, Value Iteration은 Synchronous DP라 한다. ↩︎
등장 순서는 랜덤이어도 된다. ↩︎
두 과정이 번갈아가며, 각각
와 를 만들어내는 관계 ↩︎ 두 과정이 안정화되었다는 말은, 현재 정책에 대해 대해 만들어진 가치 함수에서 탐욕적인 선택을 한 것이 현재 정책과 같다는 말이고, Bellman optimality equation에 의해 정책과 가치 함수가 각각 최적화되었음이 보장된다. ↩︎
물론 모든 RL 풀이법들이 다 Bootstrap을 사용하는 것은 아니다. ↩︎
Comments